Zoom Transcripts to CRM-Ready Sales Signals: An API-First Pipeline for Scoring and Field Extraction
A discovery call ends, Zoom drops a transcript into cloud storage, and a Slack message tells the rep their recording is ready. Three weeks later the deal slips, someone opens the opportunity to work out why, and the record says nothing the transcript didn’t already contain in plain text. Turning Zoom transcripts into CRM-ready sales signals is the work that bridges that gap: it takes the qualification evidence, the competitor mention, the buyer's description of the problem, and the commitment to a next step, and writes them into the CRM as typed fields rather than leaving them buried in a file nobody reads twice.
Transcript access isn’t the same as that. A folder full of VTT files, or a tool that emails a polished call summary, gives you a record of the conversation and stops there. The operational value shows up only when the same call produces the same structured fields every time, scored on the same scale, mapped to the same CRM objects, so RevOps can compare a deal this quarter against a deal last quarter and trust that the numbers mean the same thing. This post walks through the pipeline that does that, in the order you would build it: Zoom webhooks, transcript delivery, API-first analysis, scoring, field extraction, and the push into CRM or BI.
Why transcript delivery alone does not create operational value
The common assumption is that delivery is the product: export the transcript, hand it to RevOps, and let the team work out the rest with a spreadsheet or a one-off script. That assumption holds for exactly one quarter. Manual extraction doesn’t scale past the first handful of calls, scripts drift the moment a rep phrases an objection differently, and two analysts reading the same call will tag it two different ways. What you end up with isn’t a dataset; it’s a pile of inconsistent annotations that look like data until someone tries to aggregate them.
The deeper problem is what teams measure when they finally do build something. A pipeline that checks whether the rep said the discovery questions, hit the talk-time target, or followed the call framework produces clean-looking numbers that describe rep behaviour and almost nothing about whether the buyer understood the product or articulated a real problem. Coaching then optimises against the wrong target, because the signals being measured are about compliance rather than comprehension. The fix is a structured output contract that captures buyer understanding directly, the same way on every call. Stacking more analysis on top of the transcript doesn’t get you there; the structure has to be defined up front.
What “sales signals” means when RevOps has to use it
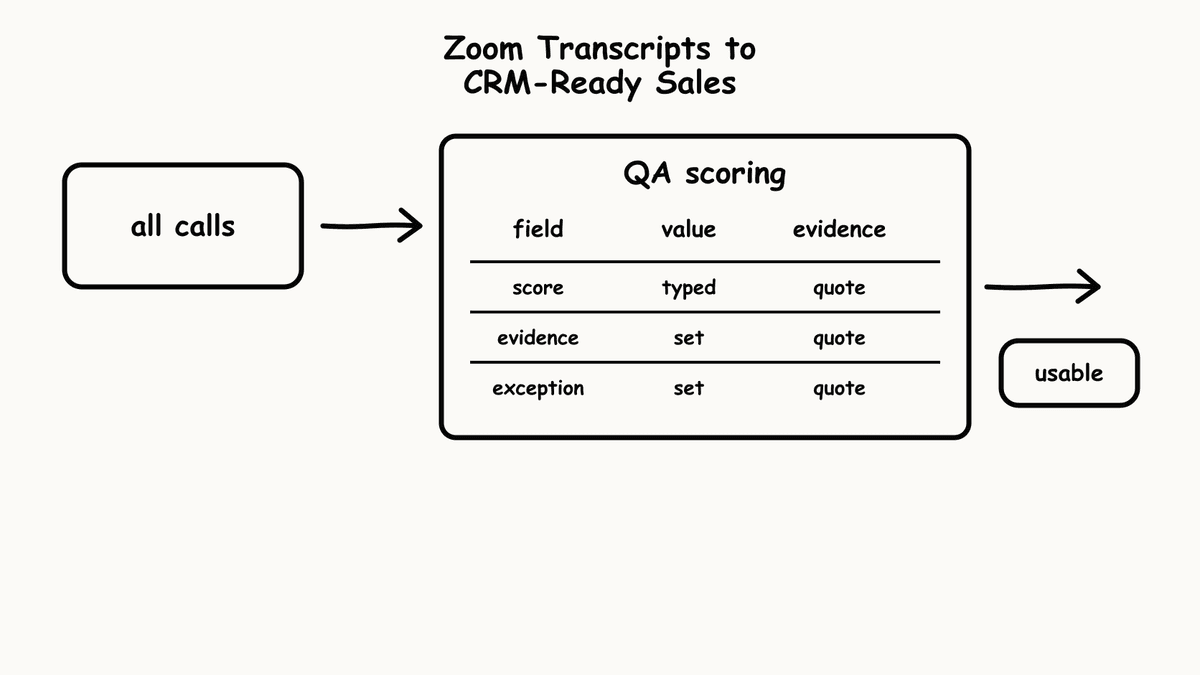
A sales signal that RevOps can operationalise is a scored or extracted field that maps cleanly onto a CRM property or a BI column. It isn’t a paragraph of prose and it isn’t a sentiment label that means something different on every call. Useful fields from a discovery call include whether the buyer articulated a quantifiable business problem, the strength of pain clarity on a defined scale, whether the economic buyer was identified and present, which competitor was named, what timeline language the buyer used, and whether the next step was confirmed with a date and an owner. Each of these answers one specific, evidence-answerable question and returns one concrete value.
The hard requirement underneath all of it is determinism: the same transcript run through the same logic has to produce the same field values every time. Free-text summarisation can’t promise that, because a model asked to “summarise the call” will phrase things differently on each pass and leave you reconciling wording instead of reading data. This is the distinction between conversation intelligence as a viewing experience and conversation intelligence as data infrastructure, and it is the line this whole pipeline is built to stay on the right side of. We have written separately about why conversation intelligence is not enablement analytics if you want the longer version of that argument.
Where Semarize sits in the pipeline
Semarize is the analysis layer in the middle of this flow. It is a conversation intelligence API that takes transcript text and returns structured JSON signals; it doesn’t record calls, store recordings, or present a rep-facing review screen, and it’s transcript-agnostic, so the Zoom transcript you already generate is a valid input with no separate capture step. Around it, Zoom handles the recording and the webhook, your automation handles routing and CRM writes, and Semarize handles the part where unstructured conversation becomes typed fields. It sits between the transcript and the opportunity record, and nothing about it competes with the CRM or the meeting platform.
The logic that does the work is defined as Bricks and Kits. A Brick is a single typed evaluation criterion: it asks one specific question about the conversation and returns one concrete value, a boolean, a score on a defined scale, an extracted string, or a categorical flag. A Kit is a versioned schema that groups related Bricks, so running a discovery Kit against a transcript returns the same shaped JSON object, one typed field per Brick, on every run. When you need a Brick to evaluate against your own qualification rules rather than a generic definition, knowledge grounding attaches your approved documents so the Brick returns its flag alongside the transcript quote and the document reference as evidence.
Setting up the Zoom webhook and transcript delivery
Zoom fires a webhook when a cloud recording finishes processing and the transcript is ready. The event is recording.completed, and its payload carries the recording metadata plus a download URL for the transcript file, which Zoom provides as VTT with speaker labels and timestamps. To enable it, create an app in the Zoom Marketplace with webhook subscriptions turned on and subscribe to recording.completed. On setup, the endpoint has to answer Zoom's validation challenge: automation platforms like Make and n8n handle that handshake in their webhook module, and a custom service responds to the verification token directly.
When the event arrives, the automation fetches the transcript from the download URL using Zoom's OAuth token, parses the VTT to recover the speaker-attributed text, and stores it against a traceable recording ID so every later field can be traced back to the call it came from. The speaker labels carry the participant names, which lets the automation separate rep turns from buyer turns using known participants or role metadata. Clean speaker separation matters more than people expect, because evaluating “did the buyer describe a quantifiable problem” depends entirely on knowing which turns belong to the buyer. The same principle holds whatever the source, and we have argued before that clean conversation inputs matter more than the model you put behind them.
API-first analysis: from transcript to scored fields
With the transcript text extracted, the automation sends it to the analysis API together with the Kit identifier. A Run is the execution of a Kit against one conversation: every Brick in the Kit is evaluated and the response comes back as a JSON object with one field per Brick, typed exactly as the Brick defines. Delivery can be a synchronous response, a webhook callback when the Run completes, incremental polling for teams processing in batches, or a historical backfill when you want to score calls that predate the pipeline. A discovery Kit response is shaped like this:
quantified_problem returns a boolean, pain_clarity_score returns a number on a defined scale, economic_buyer_present returns a boolean, competitor_named returns a categorical string, decision_timeline returns an extracted string, and next_step_confirmed returns a boolean. Because the Kit is versioned, the field names and types are a contract: downstream systems can depend on the shape, and any change to that shape arrives as an explicit new version rather than a silent break in the data. The scoring stays meaningful only if the Bricks measure buyer understanding rather than rep compliance, which is the whole point of the next section.
Validation: score understanding, not compliance
Most AI scorecards are theatre, in the sense that they measure whether a rep followed a script or produced a tidy enablement artefact and call that a quality score. A high number on that kind of scorecard tells you the rep performed the ritual; it tells you nothing about whether the buyer left the call understanding what they were buying or why it mattered. Coaching that runs off those numbers reinforces the ritual, and the score quietly stops correlating with the deals that actually close, at which point the team stops trusting it and the pipeline becomes shelfware.
The validation rule is therefore to design every scoring Brick around evidence of buyer understanding: did the buyer restate the problem in their own terms, name a quantified cost, identify who signs, or describe a real timeline driver. Grounding those Bricks against your own qualification framework keeps them honest, because each flag comes back with the transcript quote that triggered it, which means a disputed score can be audited rather than argued. Then close the loop empirically by checking whether the extracted fields correlate with outcomes: if pain_clarity_score doesn’t separate won deals from lost ones, the Brick is measuring the wrong thing and the logic gets corrected before the field is trusted in reporting. We make the longer case for this in our piece on why AI scorecards are theatre unless they measure customer understanding.

Turning Zoom transcripts into CRM-ready sales signals: pushing fields to CRM and BI
The last step routes each typed field to its destination. To write to the right opportunity, the automation links the Zoom call to the deal: the most reliable method reads an opportunity ID from the calendar metadata in the webhook payload, and a fallback matches attendee email addresses to a CRM contact and its open opportunity, with ambiguous matches queued for review so a misattributed score never corrupts a record. With the opportunity confirmed, each field writes through the CRM's update API: a PATCH to the Salesforce Opportunity object or the HubSpot Deal object, where each typed value lands in a custom property created for call-level signals.
The same JSON has a second destination. Because the Kit output is already typed and stable, it drops into a warehouse table without reshaping, one column per Brick, one row per call, which gives the data team a conversation dataset they can join against pipeline and outcome data for BI and analysis. For teams wiring this in a no-code tool, the CRM write and the webhook trigger are native modules, and our Make integration guide walks through the connections; for teams with a direct integration, the field-mapping patterns for both CRMs are covered in the CRM enrichment playbook. Either way, this is a RevOps data pipeline rather than another viewer, and the same structure runs equally well for QA, customer success, or coaching by swapping the Kit.
Semarize turns Zoom transcripts into the same CRM-ready sales signals on every call, delivered as typed JSON your CRM and warehouse can use without reshaping.
Common questions
What fields should we extract from Zoom transcripts for CRM enrichment?
Extract fields that describe buyer understanding and deal progression, not rep activity. For a discovery call, useful fields are whether the buyer articulated a quantifiable problem, a pain-clarity score on a defined scale, whether the economic buyer was present, which competitor was named, the decision timeline the buyer described, and whether a next step was confirmed with a date and owner. Each maps to a CRM property type directly: a boolean to a checkbox, a categorical to a picklist, a score to a number. Start with the handful of fields that distinguish your won deals from your lost ones, then expand once those prove stable.
How do we design scoring so it measures buyer understanding, not rep compliance?
Write each scoring criterion around evidence the buyer produced, not steps the rep performed. Instead of scoring whether the rep asked the discovery questions, score whether the buyer restated the problem in their own words, named a quantified cost, or identified who signs off. In Semarize this is a Brick grounded against your qualification framework, so each score returns with the transcript quote that triggered it. Then validate the field empirically: if a score doesn’t separate won deals from lost ones, it’s measuring the wrong thing, and you correct the logic before trusting it in reporting.
Do we need to store raw Zoom transcripts, or only the structured JSON?
For ongoing reporting and CRM enrichment, the structured JSON is what downstream systems consume, so that is the durable record most teams query day to day. Keeping the raw transcript alongside it is still worth doing for two reasons: you can re-run a newer Kit version against historical calls through backfill, and you can audit a disputed field against the source text. A practical pattern is to store the raw transcript against its recording ID in cheaper storage and keep the typed fields in the CRM and warehouse where they are actually used.
How do we keep the JSON fields stable as models and prompts change?
Treat the output as a versioned contract rather than something that can shift underneath you. In Semarize, a Kit is a versioned schema, so the field names and types stay fixed for a given version and any change to a Brick's criteria arrives as an explicit new version instead of a silent edit. That lets you compare scores across time honestly, because a dataset scored under version one and version two is marked as such rather than looking continuous while containing hidden breaks. Downstream CRM and BI mappings depend on the version, so they only change when you choose to migrate them.
Can the same Zoom pipeline serve customer success and QA as well as sales?
Yes, by routing different call types to different Kits. The webhook, transcript delivery, and field-writing steps stay identical; only the Kit changes. A sales discovery Kit writes buyer-understanding fields to the Opportunity, a customer success renewal Kit writes risk and sentiment fields to the Account, and a QA Kit writes compliance flags to a custom object. The automation picks the Kit from the meeting type, calendar category, or participant roles, so one pipeline produces the right structured signals for each team without separate infrastructure per use case.
Continue reading
Read more from Semarize
CRM Enrichment From Sales Calls: The RevOps Data Ops Playbook
Most CRM enrichment stalls at 30% field coverage because the output is unstructured - reps updating from memory, summaries stored as notes. The fix is a structured extraction pipeline: transcript to consistent fields to CRM to automation triggers. This playbook covers the schema, the routing, and the implementation in Salesforce and HubSpot.
Gong Captures the Transcript. Here’s What It Can’t Score.
Gong’s scoring runs against a fixed model — you can’t attach your product documentation, rate card, or qualification playbook to its evaluation layer. For four evaluations that matter — product accuracy, pricing audit, methodology A/B testing, and deal readiness scoring — knowledge grounding and KB isolation are the only architecture that works.
How to Get Conversation Intelligence From Zoom and Teams Without Buying Another Platform
Zoom and Teams already generate the transcripts you need. This guide shows how to get conversation intelligence from Zoom and Teams by routing those transcripts through an evaluation API, producing CRM enrichment, coaching signals, and QA coverage without adding a recording platform or paying per-seat for a duplicate transcript.