Why Clean Conversation Inputs Matter More Than Your LLM Choice
Swap the model behind a conversation intelligence pipeline for the best one on the market, feed it a transcript with no speaker labels and a criterion that asks “was this a good discovery call?”, and the output gets no more reliable. The same call still scores differently on two runs, the same fields still come back empty, and the dashboard built on top still can’t be trusted. The model was never the constraint. Clean conversation inputs, the transcript, the evaluation schema, and the delivery, decide how much signal a model can return, and a better model applied to a poor input produces marginally better noise.
Three things sit upstream of the model and set a ceiling on everything it produces: the structure of the transcript, the precision of the evaluation schema, and the reliability of delivery. Get them right and the output is consistent and comparable across calls. Get them wrong and you inherit inconsistency that no model upgrade reaches, because the problem is in the data going in rather than the intelligence applied to it. For most RevOps and sales intelligence pipelines, the order in which a team fixes these inputs matters more than which LLM it picks.
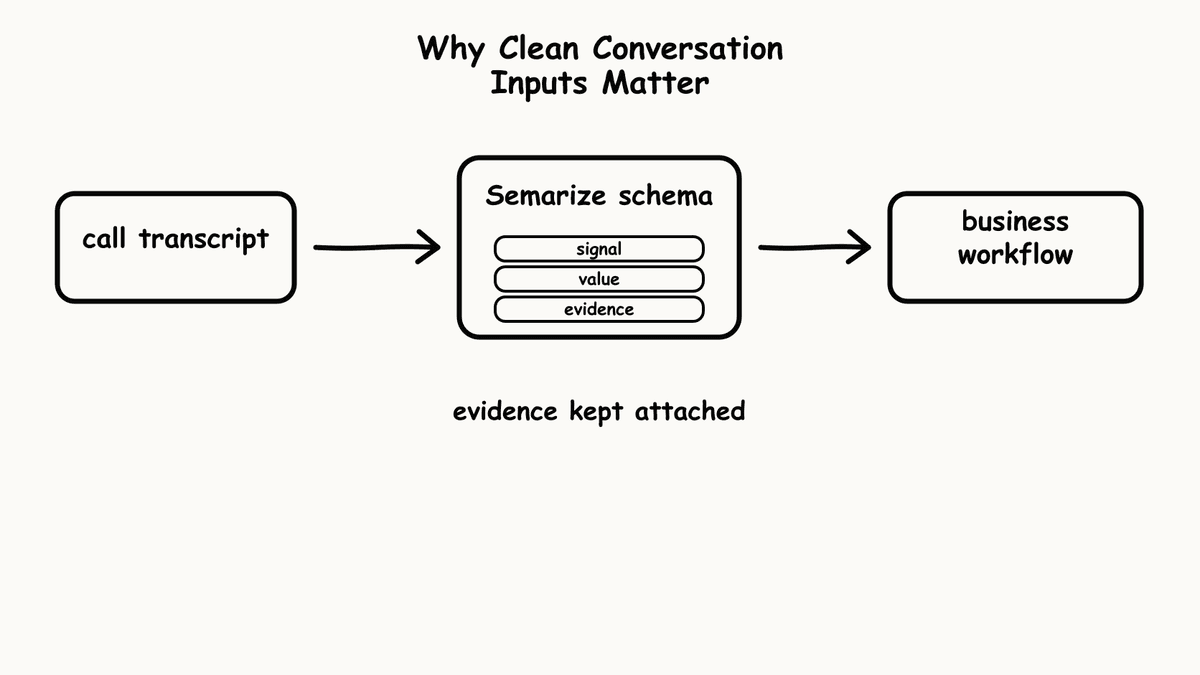
Transcript structure: the first bottleneck
A pipeline is only as good as the transcript it reads, and transcript quality is usually discussed as a transcription-accuracy question when structure is the larger issue. Accuracy matters, but a perfectly transcribed call with no speaker labels is still hard to evaluate. The structural questions are whether the transcript distinguishes speakers, whether timestamps are present, whether filler and cross-talk have been handled, and whether the format stays consistent across call types and recording platforms.
Speaker attribution moves output quality the most, because most useful criteria test for what the buyer said specifically rather than what was said in general. A criterion that asks whether the buyer named a quantifiable business problem needs the model to find the buyer's turns and judge those. Hand it an undifferentiated block, or generic labels like “Speaker 1” and “Speaker 2” with no role attached, and the model has to guess which speaker is the buyer and which is the rep. That guess adds variance to the score that has nothing to do with what happened on the call.
Consistency across call types is the quieter problem. A pipeline that scores discovery calls, demos, and renewals receives transcripts with different shapes, and a recording source that formats them all the same way keeps the evaluation layer simple. One that uses different conventions per meeting type, or shifting speaker-label patterns, pushes that variability downstream, where it surfaces as noise in fields that should have been stable.
The evaluation schema: where output quality is won or lost
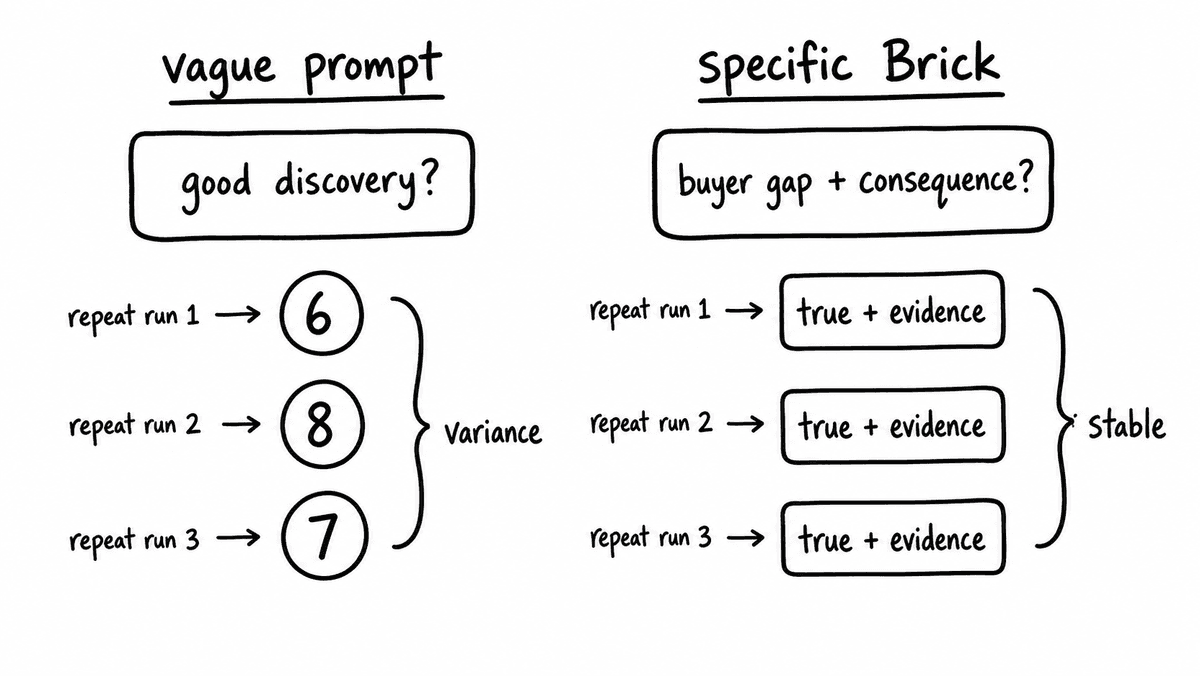
The schema, the set of criteria the model evaluates against, is the single biggest determinant of output quality, and it is where most problems actually start. A criterion like “was there good discovery?” asks the model to decide what good discovery means, apply that definition, and return a score in one move, and every run decides slightly differently. That is why the same transcript can score six, then eight, then seven across three runs with the same model: the variance is in the question, not the call.
A well-specified criterion tests for observable evidence instead. “Did the buyer describe their current state and the gap to a desired state, with a named consequence?” is answerable from the transcript in a way that “good discovery” isn’t. The specificity is what makes the result repeatable across runs and comparable across calls, and it is the idea behind Bricks in Semarize: each criterion is a single typed check that returns one concrete value, not a prose prompt that returns an interpretation. The model still does the semantic work; the Brick fixes exactly what it is being asked.
Versioning extends the same discipline across time. When criteria change, scores from before and after stop being comparable, and a schema that changes silently produces a dataset that looks continuous but hides invisible breaks wherever the logic shifted. For any reporting model that trends scores over months, that is the most common source of variance nobody can explain. Grouping criteria into a versioned Kit fixes the contract at a version and makes any change deliberate and tracked, so historical calls can be rescored against the new version rather than quietly diverging from it.
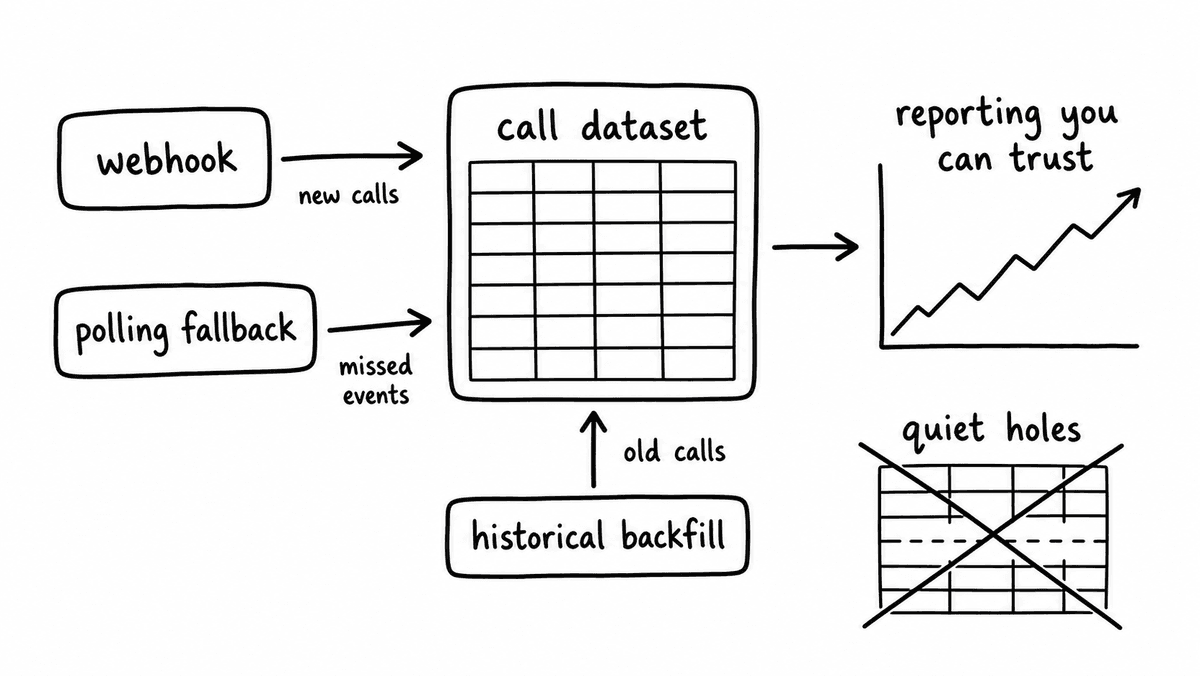
Delivery: the gap that compounds
Inconsistent delivery creates reporting gaps that are hard to see and easy to live with. A call that never scored because a webhook failed, a batch that arrived out of order behind a slow poll, a year of historical calls that was never ingested at onboarding: each one leaves a hole in the dataset that silently bends every analysis built on top of it.
Reliable delivery needs three mechanisms working together: webhooks for real-time scoring after a call ends, incremental polling as a fallback when a webhook is missed, and historical backfill for onboarding and rescoring. A pipeline with only one of the three breaks at the exact moment the missing one was needed, and because the failure is a quiet absence rather than an error, it tends to surface weeks later as a number that doesn’t add up. Building delivery on a developer API that supports all three, and testing it on real calls before committing, is what keeps the dataset whole.
Where model choice actually matters
None of this makes the model irrelevant. For criteria that need genuine semantic reasoning, judging whether a buyer's description implies a quantifiable consequence even when they used no numbers, the model determines how well the criterion is scored, and a stronger model produces fewer false negatives on the hard cases and handles messy transcript content more gracefully.
The point is where that gain lands. Model choice pays off at the margin, after the transcript is clean, the schema is specific, and delivery is whole; before that, a model upgrade barely moves output quality because the bottleneck is upstream. A team that tightens transcript structure and schema design first gets better results from the same model than a team that upgrades the model while leaving vague criteria and ragged inputs in place. The teams that feel this most are the ones running scores into reporting and warehouse workflows, because that is where inconsistent inputs turn into trends no one can trust.
The order of operations for clean inputs
The sequence is concrete. Fix the transcript source first. Define each criterion to the level of specificity that holds up across repeated runs. Make delivery complete and reliable. Then, and only then, ask whether the model serving the evaluation is the limit on the criteria that remain noisy. Most pipelines gain almost everything from the first three steps and surprisingly little from the fourth, which is the reverse of where most teams spend their attention. The discipline is resisting the model-upgrade reflex until the inputs underneath it are actually clean.
Semarize turns conversation transcripts into typed, versioned fields, so the inputs that decide output quality are the ones you control rather than the ones you hope the model sorts out.
Common questions
How do we know if our transcript quality is the bottleneck?
Run the same transcript through your evaluation pipeline twice and compare the output fields. If the same input produces different scores on separate runs, the variance is coming from the evaluation layer, specifically from criteria that are underspecified. If scores are consistent but field presence rates are low, particularly on fields that should be evaluable from most calls, the transcript structure or speaker attribution is the more likely cause. Both are diagnosable before model choice becomes relevant.
Does transcript format vary significantly between Zoom, Teams, and Gong?
Yes. The formatting, speaker-labelling conventions, timestamp granularity, and how filler words and overlapping speech are handled vary across platforms. This creates inconsistency in multi-source pipelines where calls from different platforms are evaluated against the same criteria. A normalisation step that standardises speaker labels and formatting before evaluation reduces the variance that originates from input format differences rather than from real differences in what was said on the calls.
How specific does an evaluation criterion need to be to produce consistent scores?
Specific enough that two reviewers evaluating the same transcript independently would reach the same conclusion. Criteria that fail this test in manual review will also fail it in automated evaluation. The practical design approach is to start with a behavioural claim, such as that the buyer articulated their pain clearly, and then ask what specific evidence in the transcript would confirm it. The answer to that question is the criterion that belongs in the Brick, not the behavioural claim itself.
When does upgrading the LLM actually improve call scoring output?
When the remaining noisy fields are ones that require semantic reasoning the current model handles poorly: understanding implication rather than explicit statement, interpreting indirect buyer signals, or handling unusual vocabulary and accent patterns. If consistent fields are still noisy after the schema is well-specified and the transcript is clean, the model is likely the constraint. If the noisy fields are ones where the criteria are vague or the transcript structure is inconsistent, the model isn’t the bottleneck and upgrading it will have limited effect.
Continue reading
Read more from Semarize
Bricks and Kits: the mechanism for stable conversation evaluation
Freeform prompts produce inconsistent evaluation results - scores drift, output shapes change, and you can't tell whether coaching improved anything or whether the rubric moved. Bricks define a locked evaluation schema: one question, one output type. Kits group them into reusable evaluation workflows. The result is schema-stable conversation analysis you control.
AI Scorecards Don't Disagree. Your Prompt Does.
Inconsistent AI scorecards aren't an AI problem - they're a process failure. Freeform prompts ask the model to re-interpret evaluation criteria on every run, and that interpretation drifts with phrasing, model updates, and context. The fix is an evaluation contract: a locked schema with defined output types that produces the same result on the same call, every time.
Conversation Intelligence Doesn't Fail on Calls. It Fails on Knowledge.
Early CI tools were built on ML classifiers - talk ratios, question counts, keyword detection. LLMs changed what's possible. But they introduced a new risk: model knowledge. When scoring runs against what the AI infers from training rather than your pricing, ICP criteria, and qualification playbooks, outputs are plausible and wrong.