Gong Captures the Transcript. Here’s What It Can’t Score.
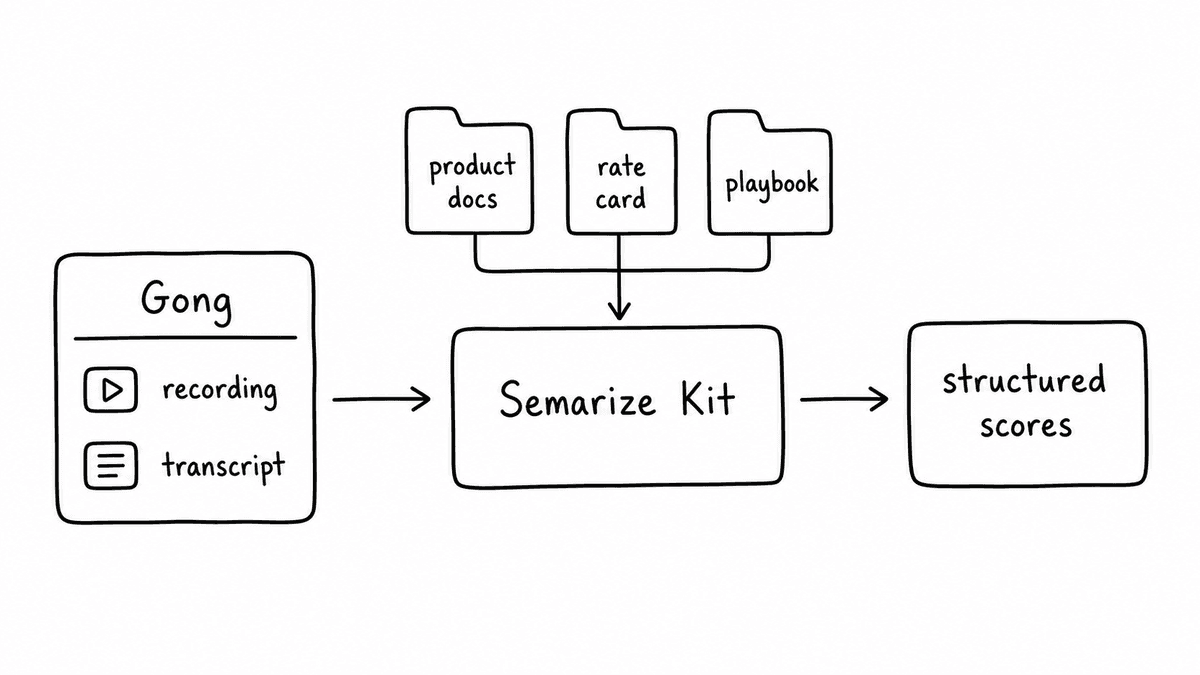
Gong is excellent at what it does: recording calls, transcribing them, surfacing aggregate signals, and populating deal boards with activity data. The architecture it's built on has one structural constraint: its scoring runs against a fixed model. You can't attach your product documentation, your rate card, your qualification playbook, or your competitive battle cards to a Gong evaluation. The signals you get back reflect what the model infers from training - not what your business defines as correct.
For teams that need evaluations grounded in their own knowledge, that constraint is the whole problem. This article covers what that means in practice, why the architecture behind it matters, and four specific evaluations - with examples from the Gong data guide - that Gong's scoring layer cannot support.
Model knowledge versus your knowledge
When an LLM evaluates a call without your documents, it works from what it knows from training: a generalised view of how B2B sales works, what pricing structures look like, what qualification criteria typically require. This is model knowledge. It produces outputs that look plausible - the scores seem reasonable, the coaching summaries read sensibly - but they're not checked against your reality. A rep quoted the wrong plan tier looks fine by the model's standards, because the model doesn't have your rate card. A deal the model qualifies might not meet your criteria.
Knowledge grounding fixes this by attaching your documents to the evaluation: your product docs, your pricing model, your methodology. Scoring runs against those documents, not against what the model assumes is generally true. When your pricing changes, you update the document - the evaluation logic stays the same, and the accuracy stays current.
Gong doesn't have this capability. Its evaluation layer is closed. The four use cases below each require it.
The second problem: attention interference
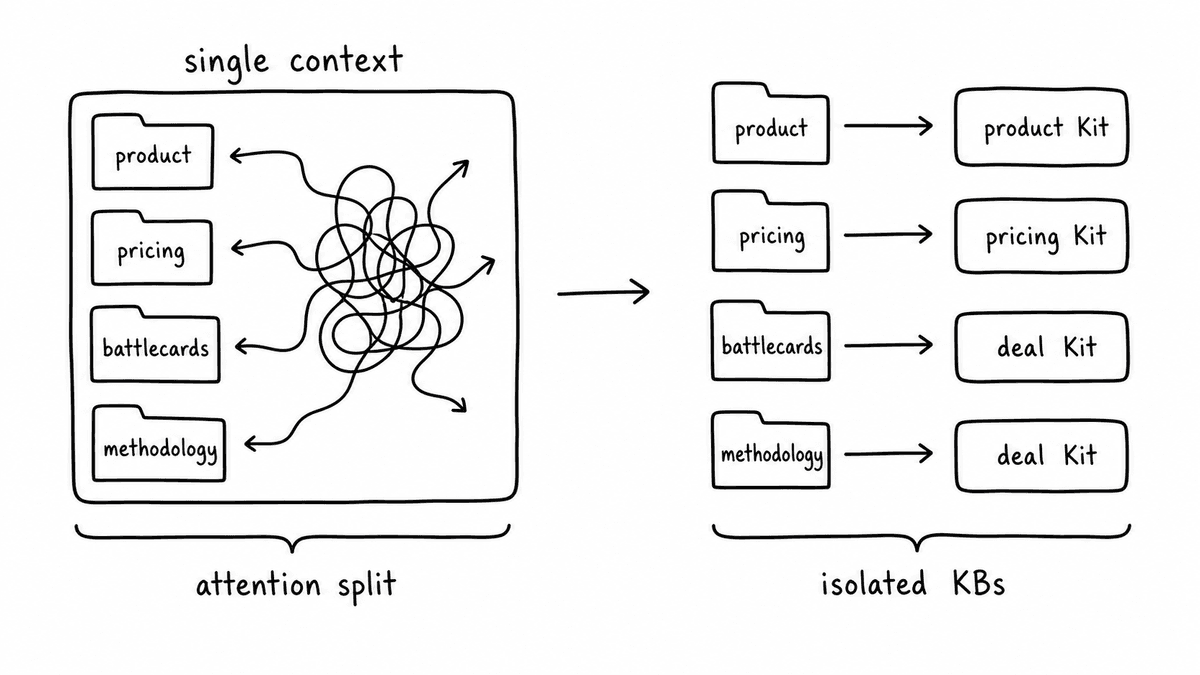
Even if you could attach knowledge to a single evaluation context, loading everything at once is the wrong approach. When multiple knowledge bases are present in one evaluation - product documentation, pricing model, competitive positioning, and qualification playbook all at once - the model's attention is distributed across all of them. A pricing accuracy check becomes less precise when it's simultaneously tracking product features and battle cards. A qualification check gets noisier when irrelevant commercial context is in scope.
This is attention interference: the dilution of the model's focus when the knowledge context is broader than the evaluation requires. The result isn't catastrophic failure - it's degraded precision. Evaluations that should be crisp and specific drift toward softer, less reliable outputs.
The solution is knowledge base isolation: running each evaluation type against its own scoped knowledge base. The product accuracy check attaches only the product documentation. The pricing audit attaches only the rate card and discount authority matrix. The qualification evaluation attaches only the methodology document. Each evaluation gets exactly the context it needs, and nothing it doesn't.
Semarize's Kit architecture is built around this. Each Kit attaches its own knowledge base. You don't have a single evaluation context trying to cover everything - you have scoped evaluations, each grounded in the right knowledge, running independently without cross-contamination.
Four evaluations that require knowledge grounding
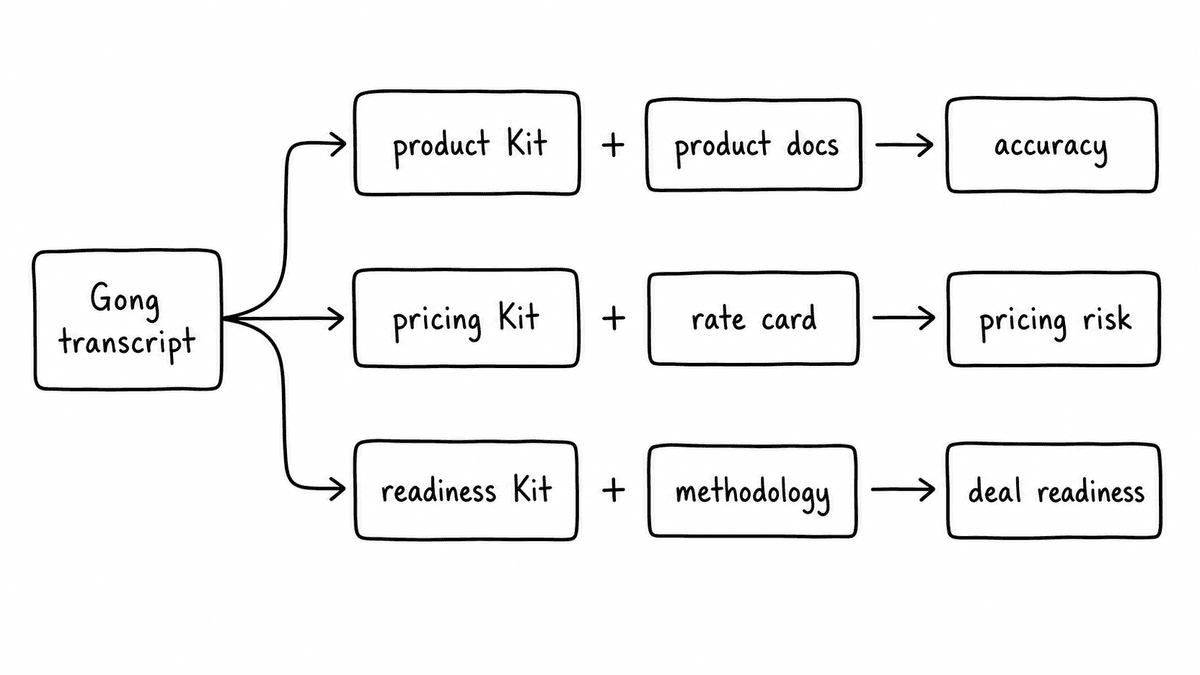
Each of the following use cases is taken directly from the Gong data guide - examples of what teams build once they're routing Gong transcripts into an evaluation layer that supports knowledge grounding.
1. Product knowledge accuracy check
Reps are quoting your product continuously across dozens of calls every week. What they say about features, plan availability, and capability drifts from what your documentation says - sometimes because they were trained on an old version, sometimes because they're simplifying, sometimes because they're wrong. A rep telling a prospect “SSO is available on all plans” when your docs say Enterprise only is a claim that creates expectations your product won't meet at closing.
A product accuracy Kit attaches your product documentation as its knowledge base and evaluates every claim a rep makes against it. When the transcript and the docs don't align, it flags the discrepancy with the exact quote as evidence. Product marketing gets a weekly accuracy report; enablement materials update where gaps appear. This check requires your documentation. Without it, the model doesn't know what your plans include.
2. Pricing and packaging accuracy audit
Pricing changes propagate slowly. A packaging update in January still shows up in rep calls in March. Reps quoting deprecated tiers, exceeding their discount authority, or bundling add-ons at old prices are commercial risks that surface in contracts - not on scorecards. By then, the damage is done.
A pricing audit Kit attaches your current rate card and discount authority matrix. Every call gets scored for pricing accuracy, discount compliance, and packaging currency. Finance gets a weekly report of commercial risk exposure from pricing errors, identified before contracts go out. The evaluation is completely data-dependent: without your rate card, there's no check to run.
3. Methodology A/B testing
When your team is split on discovery approach - some reps lead with business impact questions, others dive straight into technical requirements - the question of which performs better can be answered with data. But only if you can measure each approach consistently and independently.
Two Kits, one per approach: an impact-led Kit that scores for pain quantification, stakeholder mapping, and outcome framing; a technical-led Kit that scores for requirements gathering, integration questions, and feature depth. Both run across all discovery calls. Tag each call by dominant approach, compare stage-two conversion in your CRM, and the data tells you which methodology to standardise on.
This is where KB isolation matters most. A single evaluation context trying to score both approaches simultaneously conflates them - the model can't cleanly separate the two evaluation schemas when they're competing for attention in the same context. With separate, scoped Kits, the comparison is clean.
4. Conversation-grounded deal readiness scoring
CRM stage labels reflect what a rep reported, not what was established in the conversation. A deal in Stage 3 may or may not have confirmed budget, identified a decision maker with actual authority, or quantified the buyer's pain with numbers. The stage says it did; the conversation may tell a different story.
A deal readiness Kit attaches your qualification methodology document and evaluates each call against it. Not whether the words appeared in the transcript, but whether the criteria were meaningfully met. Budget confirmed means the buyer committed to a number, not that budget was mentioned. Decision maker identified means a name or role with authority was cited, not that “our team” was referenced. The output is a per-deal readiness score grounded in what the buyer actually said, with evidence spans showing exactly what in the transcript supported each signal.
How isolated knowledge bases stay maintainable
Each Kit owns its knowledge base. When your pricing changes, you update the pricing KB - the product accuracy Kit and the methodology Kit are unaffected. When you update your qualification criteria, only the deal readiness Kit needs revalidation. Isolated KBs have clear owners, clear update cadences, and clear scopes.
Contrast this with a single evaluation context that contains all your knowledge at once. When pricing changes, which evaluations are affected? All of them, potentially, because the pricing context is present everywhere. Tracking down which scoring outputs need revalidation becomes opaque. Isolated KBs solve this directly: the scope of change is exactly the Kit that owns the KB, and nothing else.
Getting the transcript out of Gong
Gong owns the recording and the transcript. Getting the transcript via API is well-documented: the dedicated guide at /resources/get-your-data/gong covers authentication, the exact endpoints, the three extraction patterns (historical backfill, incremental polling, and webhook-triggered), and the common gotchas around rate limits and transcript availability timing.
Once you have the transcript, it's the input. Which Kit you run it through - and which knowledge base that Kit attaches - determines what you get back. The same transcript can go to a product accuracy Kit, a pricing Kit, and a deal readiness Kit in parallel. Each returns structured output scoped to its domain, grounded in the right knowledge, without cross-contamination between them.
What to do next
Start with one evaluation type - the one where wrong answers in CRM are currently costing the most. Build the Kit in Semarize, attach the relevant knowledge base, run it against a sample of recent Gong transcripts, and review the evidence spans. The evidence shows exactly what in the transcript supported each result, or exactly where the gap appeared.
Once the first Kit is validated, the remaining ones follow the same pattern. Each adds an isolated evaluation layer without affecting the others. The goal is a set of evaluations grounded in your reality - not in what a model infers about how sales generally works.
Semarize turns Gong transcripts into structured output grounded in your knowledge. Define the schema, attach the right KB per Kit, and score every call against what your business defines as correct.
Common questions
Why can't Gong do knowledge-grounded evaluation?
Gong's evaluation layer is built on its own trained model - you can't attach your documents to it. The signals it returns reflect what the model infers from training data, not your pricing, your product documentation, or your qualification criteria. For evaluations that require your knowledge to be accurate, that's a structural constraint, not a configuration problem.
What is attention interference and why does it matter for evaluation accuracy?
When multiple knowledge bases are loaded into a single LLM evaluation context, the model distributes attention across all of them. A pricing accuracy check that's also tracking product features, competitive positioning, and qualification criteria is doing all of them less precisely than it would if scoped to just the rate card. KB isolation - running each evaluation type against its own scoped knowledge base - prevents this dilution. The check is more accurate because it's focused on exactly the knowledge it needs.
Which knowledge base should we attach first?
The one where inaccurate scoring does the most immediate damage. For most teams that's either product accuracy (incorrect claims create churn risk that surfaces months later) or pricing (errors reach contracts before anyone catches them). Start there, validate the extraction against evidence spans across a sample of recent calls, then expand to additional Kits.
How do isolated knowledge bases work in practice?
Each Kit in Semarize attaches its own knowledge base - a set of documents the evaluation retrieves from during scoring. A product accuracy Kit attaches your product docs. A pricing Kit attaches your rate card. A deal readiness Kit attaches your qualification methodology. The Kits run independently: updating one KB doesn't affect any other, and each evaluation is scoped to only the context it needs.
Can I run multiple Kits against the same Gong transcript?
Yes. Send the same transcript to multiple Kits via separate API calls - in parallel if your automation supports it. Each returns structured output scoped to its evaluation domain. Product accuracy, pricing accuracy, and qualification scores arrive as separate outputs, each grounded in the right knowledge, without cross-contamination between them.
Continue reading
Read more from Semarize
Conversation Intelligence Doesn't Fail on Calls. It Fails on Knowledge.
Early CI tools were built on ML classifiers - talk ratios, question counts, keyword detection. LLMs changed what's possible. But they introduced a new risk: model knowledge. When scoring runs against what the AI infers from training rather than your pricing, ICP criteria, and qualification playbooks, outputs are plausible and wrong.
AI Call Scoring Is Theatre Without a Knowledge Layer
AI call scoring that runs on a good LLM with a well-written rubric can look accurate until you test it against what actually happened. The failure isn't one missing check. Every commercial dimension worth assessing has multiple facets, and each facet requires its own grounded document to evaluate properly. A knowledge layer is what makes scoring checkable across all of them rather than plausible about none of them.
Bricks and Kits: the mechanism for stable conversation evaluation
Freeform prompts produce inconsistent evaluation results - scores drift, output shapes change, and you can't tell whether coaching improved anything or whether the rubric moved. Bricks define a locked evaluation schema: one question, one output type. Kits group them into reusable evaluation workflows. The result is schema-stable conversation analysis you control.