The 2026 Sales Call QA Stack That Actually Scales: AI Scoring, API-First Tools, and Auditable Results
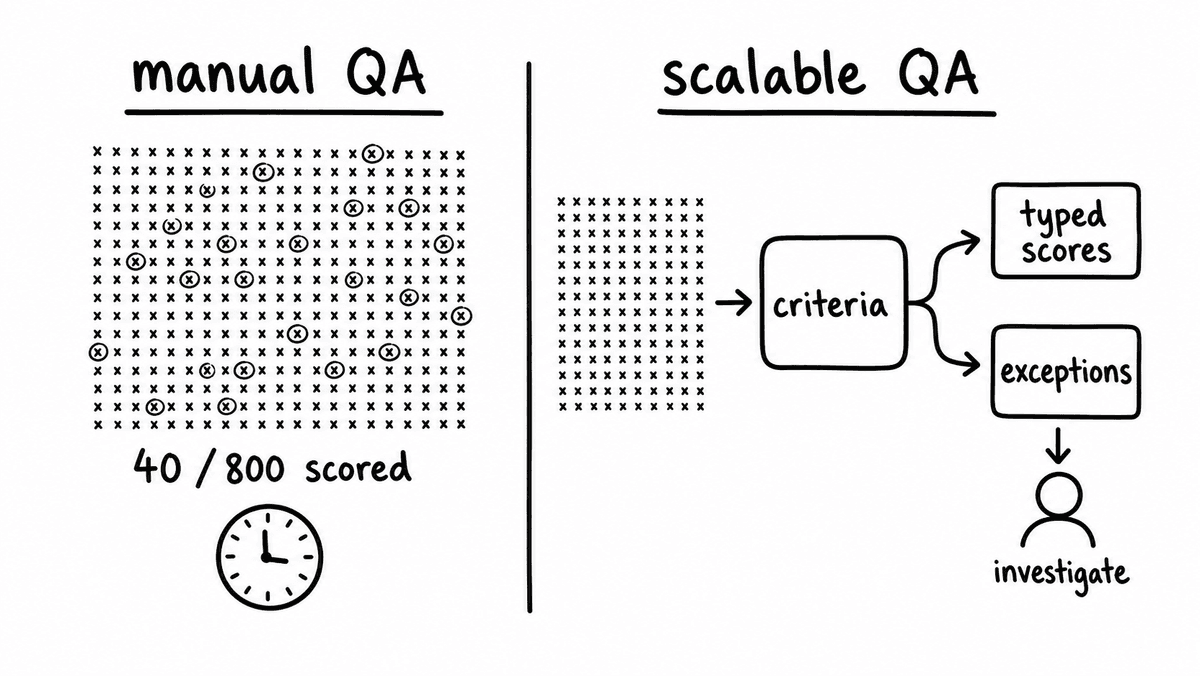
Two QA analysts sit down on a Monday with a quarter's worth of recordings and a rubric, and by Friday they have listened to maybe forty calls out of the eight hundred the team booked. That is the real ceiling on most sales call QA work, and it’s the reason a sales call QA stack built around reviewer time can only ever sample. The forty calls get a verdict; the other seven hundred and sixty go unscored, and any pattern that only shows up across the full set, a phrase reps drop when a deal slips, a disclosure that goes missing under pressure, stays invisible. Coverage at that level tells you what happened on the calls someone had time to open, not what’s happening on your calls.
A stack that scales removes reviewer time from the coverage equation. Every call gets scored against the same defined criteria, automatically, the moment the transcript lands, and the analysts move from listening to investigating: the calls that failed a check, the reps drifting on one criterion, the compliance gaps that need a person to judge. The tools that make this work in 2026 are API-first, return structured output you can audit rather than a single AI number, and hand reviewers exceptions instead of a backlog. Below is what each option does, where it fits, and where it doesn’t.
The short answer: what a 2026 sales call QA stack needs
A QA stack that scales has four jobs, and no single product does all four well. You need a transcript source that delivers speaker-attributed text reliably, which is what Gong, Chorus, Fathom, and native Zoom or Teams transcription already do. You need a scoring layer that evaluates every transcript against criteria you define and returns auditable, typed results, which is where Semarize sits. You need a destination that stores those results so they join to deal data, whether that is your warehouse, your CRM, or Airtable. And you need a review surface that shows analysts the exceptions worth their attention. The recording platforms are strong at the first job and increasingly offer their own AI scores; those scores are useful for coaching but harder to defend in an audit because the criteria and the evidence behind them aren’t exposed as data. The best tool for the scoring layer is the one that turns a transcript into fields you can trace back to a specific criterion and a specific quote, not a pretty number on a dashboard.
The four-layer sales call QA stack at a glance
Each layer has a different requirement, and the mistake teams make is asking one tool to cover two layers it was never built for. Here is the shape of the stack and what each part has to do.
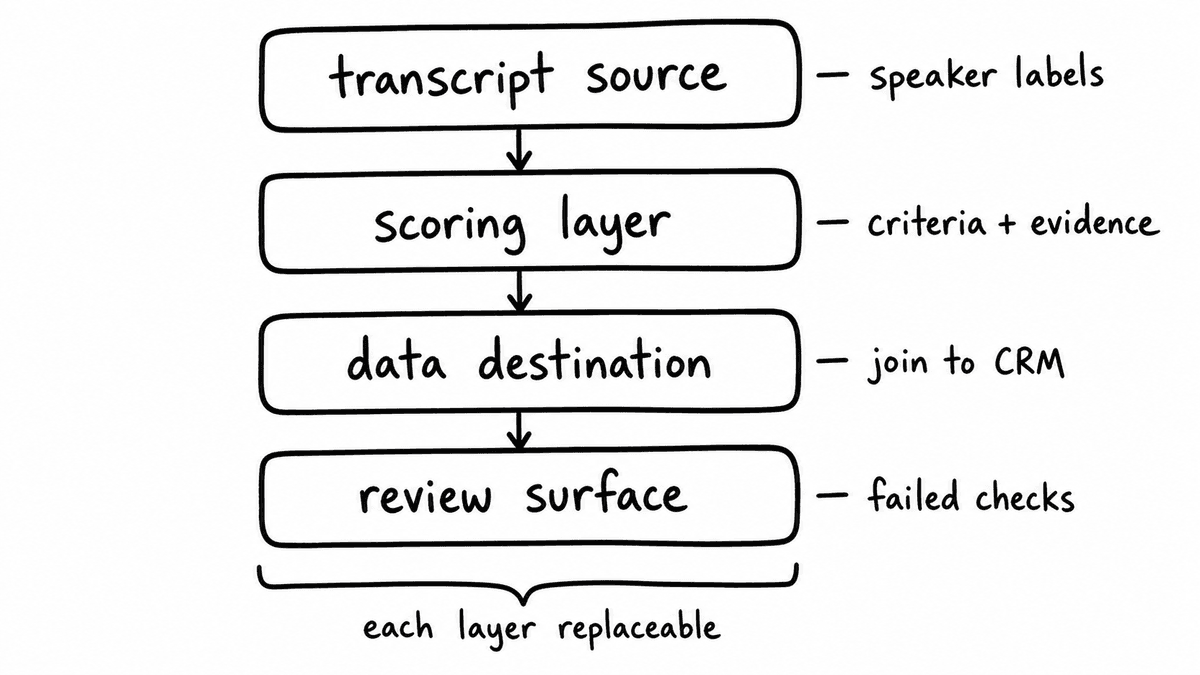
| Layer | What it does | What it has to get right | Common tools |
|---|---|---|---|
| Transcript source | Captures and delivers speaker-attributed call text | Speaker labels, consistent format, webhook delivery | Gong, Chorus, Fathom, Zoom, Teams |
| Scoring layer | Evaluates each transcript against your rubric and returns typed fields with evidence | Criteria you define, stable output shape, versioning, auditable evidence | Semarize |
| Data destination | Stores scored fields so they join to deals and reps | Queryable, joinable to CRM, stable schema | BigQuery, Snowflake, Salesforce, HubSpot, Airtable |
| Review surface | Shows analysts the exceptions and patterns worth acting on | Filter by failed criterion, rep, call type, date, score | Airtable, BI tools, internal apps |
Layer one: the transcript source
The transcript source is whatever records the call and delivers speaker-attributed text. For most teams this is already decided, and the good news is the QA stack doesn’t require changing it. Gong and Chorus capture calls, attribute speakers, and expose transcripts through their APIs. Fathom and similar meeting recorders do the same for teams that prefer a lighter footprint. Zoom and Microsoft Teams both produce native transcripts and deliver them by webhook after the call ends, which covers teams that never adopted a dedicated platform.
What the QA stack asks of this layer is narrow: speaker attribution, so the scoring layer can read buyer turns and rep turns separately; a consistent format across call types; and reliable delivery so scoring triggers without anyone exporting a file. Because the scoring layer is transcript-agnostic, you can run QA on calls from a mix of sources without standardising on one recorder, which matters for teams where field reps use Zoom and the inside team lives in Gong. The detail of running QA across mixed platforms is covered in analysing Zoom and Teams calls without a new platform.
Best fit and not best fit
A dedicated platform like Gong or Chorus is the best fit when you also want rep-facing call review, deal boards, and coaching workflows in one place, and you are willing to pay platform pricing for them. Native Zoom or Teams transcription is the best fit when you want call text with no new vendor and minimal cost. None of these is the best fit as your scoring layer for auditable QA, because their built-in AI scores apply categories the vendor chose and don’t expose the per-criterion evidence an audit needs. Use them for what they are good at, capture, and pass the transcript downstream for scoring.
Layer two: the scoring layer and why it decides the whole stack
Scoring is the layer that determines whether your QA programme is auditable or merely automated. The choice here is between vendor-defined scoring and criteria you define yourself. Vendor-defined scoring, the kind built into most recording platforms, runs the platform's model and returns scores against categories the vendor decided to measure. That is fine for a rep glancing at how a call went. It’s harder to stand behind when a compliance reviewer asks why a call passed, because the criterion and the evidence behind the number aren’t available as data you can inspect.
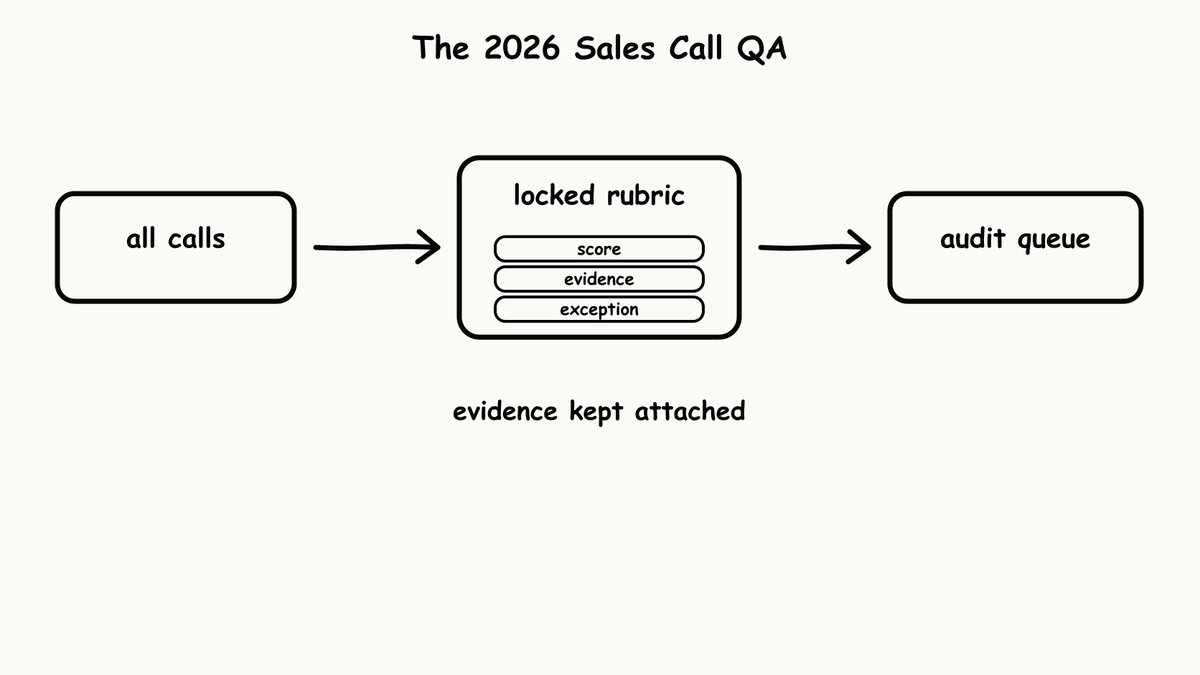
Criteria you define yourself change that. Semarize is a conversation intelligence API that takes transcript text in and returns structured JSON out, evaluated against criteria your team writes. The unit of evaluation is a Brick: a single typed criterion that asks one evidence-answerable question about a call and returns one concrete value, a boolean, a score on a scale you set, an extracted string, or a categorical flag. A Brick doesn’t write a paragraph about the call. It answers, for example, whether the rep confirmed a next step, and returns true or false with the transcript quote that justifies it. That quote is what makes the result auditable: a QA verdict you can trace to a specific criterion applied to specific words, rather than a number whose reasoning is sealed.
Related Bricks group into a Kit, a versioned schema that returns the same shaped object on every run, one typed field per Brick. Versioning is the part that protects a long-running QA programme: a score from this quarter and a score from last quarter were produced against the same criteria, and when the criteria change, the version changes too, so nothing shifts silently underneath a trend chart or a training before-and-after. For criteria tied to your own rules, knowledge grounding lets you attach your approved playbook or compliance document to the Kit, so the Bricks evaluate against your wording and each result comes back with the transcript quote and the document reference together. The shift from sampled to complete that this enables is covered in scoring 100% of calls without manual review.
Best fit and not best fit
A structured-output scoring layer is the best fit when QA results have to survive scrutiny: compliance reviews, rep performance discussions, audits where someone will ask to see the evidence behind a verdict. It’s the best fit for teams that want the same fields on every call, across the full set, joinable to deal data. It isn’t the best fit if all you want is a rough coaching impression a manager can read in passing, where a built-in platform score is faster to stand up and good enough. And it isn’t a recorder, a transcription engine, or a rep-facing review screen; it scores the transcript and returns data, and it expects the capture and the interface to live elsewhere.
Layer three: the data destination
Scored fields have to land somewhere they can be queried and joined, and the right destination depends on what the team does with QA results. A warehouse table in BigQuery or Snowflake is the best fit when the data team wants to join QA scores to pipeline and rep performance and build the analysis in a BI tool; the structured fields drop straight into a typed schema, which is the pattern described in turning conversation data into a warehouse of typed call fields. Writing scored fields onto Salesforce or HubSpot opportunity records is the best fit when QA signal should sit next to the deal it describes, so a manager reviewing an opportunity sees the call quality alongside the stage. Airtable is the best fit as a starting point, because linked records, filtering, and grouping give a QA team a working surface without building anything.
Whichever destination you pick, the requirement is the same: the field schema has to be stable so automated reports don’t break when the scoring criteria evolve. This is exactly what Kit versioning provides upstream. Field names and types stay fixed within a version, and a deliberate version bump is the only thing that changes them, so the destination schema never moves without a decision behind it. Delivery into these systems runs by webhook for live calls, incremental polling for steady backfill, and a one-off historical backfill when you want to score the archive before going forward.
Layer four: the review surface
Once every call is scored, no analyst can read every scored call, so the review surface exists to show them the exceptions. The views that make QA data act on themselves are a filter by failed criterion, a grouping by rep that shows pass rate per check, and a trend that tracks how a given criterion has moved over time. A criterion failing across half the team is a process problem, not an individual one, and full coverage is what makes that distinction visible in the first place. For most teams Airtable's own views handle this with no development. For teams that want a tailored surface, a lightweight internal app built on the same data, wired through an automation tool like Make, gives analysts exactly the views they use and nothing they do not.
The review surface stays separable from the data and scoring layers, which is the point of keeping them distinct. You can rebuild the interface, swap Airtable for a BI dashboard, or hand different views to compliance and to sales managers without touching how calls are scored or stored. That separation is also why a QA stack assembled this way doesn’t lock you into a single platform's opinion of what a good call looks like; the criteria, the data, and the surface are each yours to change.
Where Semarize fits, and where it doesn’t
Semarize is the scoring layer, and only that layer, on purpose. It’s for teams that want conversation intelligence as data infrastructure: typed JSON they can audit, join, and route, rather than another recording or dashboard product. It’s supplemental to Gong and Chorus and adds a structured-output layer they don’t expose natively, so it sits behind them rather than against them. If you want QA scores you can defend with evidence, the same fields on every call across full coverage, and a contract that doesn’t change silently between quarters, that is the job it does. This frames the wider category difference set out in why conversation intelligence isn’t enablement analytics, and the RevOps angle is developed further on the QA and compliance use case.
It isn’t the right tool if you need a meeting recorder, a place to store call audio, a coaching dashboard your reps log into, a CRM, a transcription engine, or a rep-facing call-review screen. Those are real needs, and other tools in the stack serve them well. Semarize processes the transcript after the call and returns structured signals; the capture, the storage, and the interface belong to the layers around it. Building the stack this way keeps each part replaceable and keeps the scoring honest, because the criterion and the evidence are always on the table.
Semarize is the scoring and auditability layer in a sales call QA stack: transcript in, typed JSON out, every result traceable to a criterion and a quote.
Common questions
What is a sales call QA stack?
A sales call QA stack is the set of tools that takes a recorded call from capture through to a reviewed verdict. It has four layers: a transcript source that delivers speaker-attributed text, a scoring layer that evaluates every call against defined criteria, a destination that stores the scored fields so they join to deals and reps, and a review surface that shows analysts the exceptions. The point of treating it as a stack is that no single product does all four jobs well, so each layer can be the right tool for what it does and replaced without rebuilding the rest.
Does automated scoring replace human QA review?
No. Automated scoring fixes the coverage and consistency problem: every call is scored against the same criteria without reviewer time deciding which calls get seen. Human review handles judgement: failed criteria need context, patterns need interpretation, and coaching decisions need a person to own them. The shift is from analysts spending their time selecting and listening to calls, to spending it acting on the exceptions the scoring layer surfaces. Coverage goes up and reviewer time per call goes down, but the human stays where the judgement is.
Why use a separate scoring layer instead of the AI scores in Gong or Chorus?
Built-in platform scores apply categories the vendor chose and return a number without exposing the criterion or the evidence behind it, which is fine for a quick coaching read but hard to defend in an audit. A separate scoring layer evaluates calls against criteria you define and returns typed fields, each with the transcript quote that justifies it. Semarize is supplemental to Gong and Chorus, not a replacement: it takes the transcripts they capture and adds the structured, auditable output they don’t expose natively, so you keep the recorder and gain the evidence.
How does schema versioning keep QA reporting stable?
A Kit is a versioned schema that returns the same shaped JSON object on every run, one typed field per Brick. Within a version, field names and types don’t change, so the warehouse table, CRM mapping, or Airtable view downstream stays valid and automated reports don’t break. When you refine the criteria, the version changes deliberately, which makes the contract change explicit rather than silent. That is what lets you compare a score from this quarter with one from last quarter and trust that both were produced against the same definition.
What happens when a call looks scored incorrectly?
Every Brick returns the evidence that produced its score alongside the score, so when a result looks wrong you read the transcript quote it relied on. That tells you whether the criterion was applied correctly or whether the criterion itself was ambiguous and needs tightening. If the wording was unclear, you update the Brick and rerun it against the affected calls to get a corrected dataset. That loop sharpens the criteria over time without anyone re-listening to the whole archive, which is the difference between auditable scoring and a black-box number you can’t interrogate.
Continue reading
Read more from Semarize
100% QA Scoring Without Manual Review: Deterministic Rubrics for Every Call
Manual QA sampling at 2–5% has two problems: coverage and consistency. Automated scoring with deterministic rubrics solves both - every call gets scored the same way, with no reviewer required to generate the result. The shift isn't just efficiency - it changes what coaching is built from and turns compliance verification from sampling into complete coverage.
Automated Sales Call Scoring
Most automated call scoring measures whether reps followed a script. Script compliance isn't the same as buyer understanding, and the scorecard that improves while win rates stagnate is the clearest sign the rubric is measuring the wrong thing.
Bricks and Kits: the mechanism for stable conversation evaluation
Freeform prompts produce inconsistent evaluation results - scores drift, output shapes change, and you can't tell whether coaching improved anything or whether the rubric moved. Bricks define a locked evaluation schema: one question, one output type. Kits group them into reusable evaluation workflows. The result is schema-stable conversation analysis you control.