Automated Sales Call Scoring
Automated call scoring isn’t broken. The rubric is. Almost every implementation scores whether reps followed the script, asked open-ended questions, and covered the right features at the right moment. Those are rep behaviour metrics, and rep behaviour metrics tell you almost nothing about whether the deal is real.
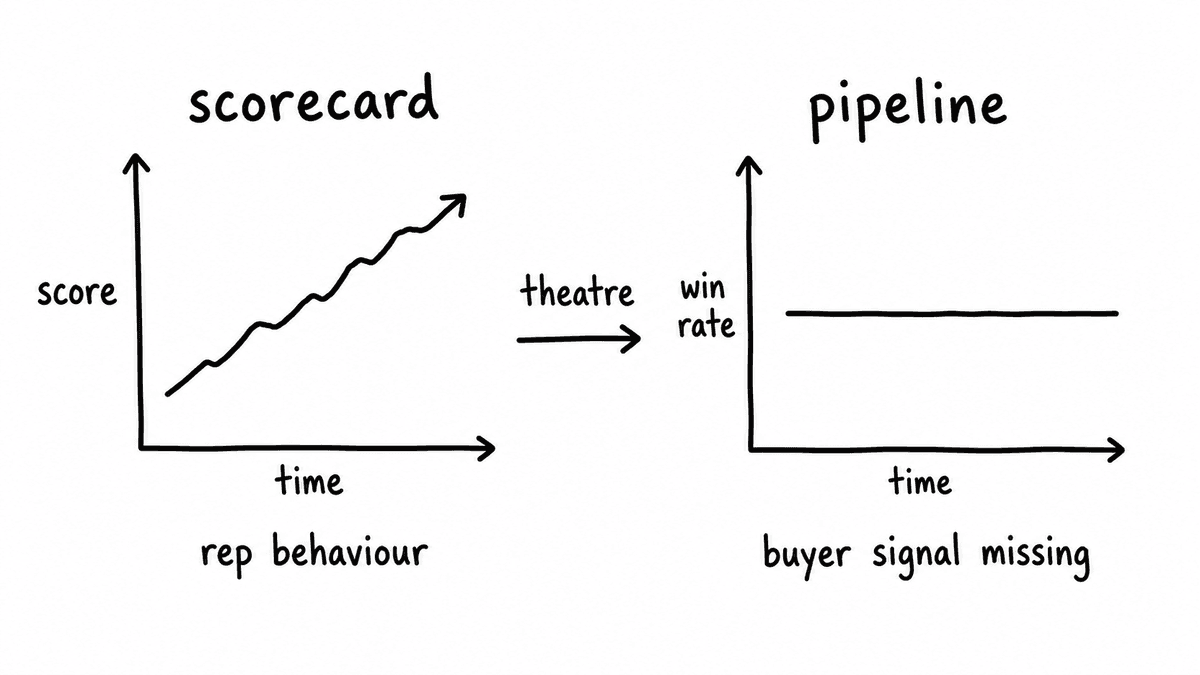
The result is a scorecard that improves over time and a pipeline that doesn’t. Reps learn what the model rewards and adjust accordingly, so scores drift upward while win rates stay flat. The coaching conversations get louder and the signals get worse, because the system is measuring a performance rather than a purchase decision.
What automated call scoring actually is
Automated call scoring isn’t just giving a call a number. It means returning a structured value for a specific question about that call that can be machine read. Not a sentiment average, not a keyword count, a typed field that answers something concrete: did the buyer describe a quantifiable problem, did they name a decision maker, did they commit to a specific next step. The same question, applied consistently to every transcript, producing the same type of output on every run.
That definition matters because it rules out most of what gets sold as automated scoring. A numeric "call quality score" that summarises a hundred signals into one number isn’t a scoring system, it’s a compression function, and compressed signals can’t be routed, trended, or acted on individually. Structured rubric output means one field per question, typed and consistent, ready to land in a CRM column or trigger a workflow rule without a human in the loop.
The same logic applies across calls, meetings, and chat threads once transcript ingestion is in place. The evidence patterns differ by channel, but the underlying questions are often the same, and a well-defined rubric field handles partial evidence by returning null or low confidence rather than guessing.
Why most AI scorecards are theatre
The core problem is what the criteria are measuring: Teams buy conversation intelligence to improve coaching, then end up coaching off signals that describe the rep rather than the deal. Whether the rep asked open-ended questions is a proxy for discovery quality, but a weak one: a rep can run a textbook discovery call with a buyer who has no real problem and no real budget, and the scorecard won’t know the difference.
The theatre problem runs deeper than measuring the wrong subject. When the scorecard rewards rep behaviour, reps optimise for the scorecard, scores go up and coaching conversations get shorter because managers can point to the numbers. Win rates stay where they were because the metrics are accurate but the system is measuring the performance rather than the deal, and nobody notices until the forecast falls apart.
Running a retrospective on your closed-won and closed-lost deals is the fastest way to test whether your current criteria are doing any work. If the call scores aren’t meaningfully differentiated between the two groups, the criteria are measuring rep behaviour proxies and the rubric needs rebuilding from the buyer side up.
The human review trap
The standard response to model uncertainty is to add a human review layer: a manager samples ten percent of calls, checks the scores, and approves or overrides. The logic is sound but the practice breaks at scale in two ways:
First, ten percent coverage with selection bias isn’t a representative signal about the full call set, it’s a signal about the calls someone decided to look at.
Second, manual review creates a feedback loop that’s weeks behind the deal, which means coaching decisions arrive after the moment they could have changed anything.
The deeper issue is that human review can’t be the structural trust mechanism for a scoring system. It can calibrate a new rubric and catch exception cases, but it can't be the thing that makes every output trustworthy, because that requirement collapses back into reviewing every call and the automation adds nothing. The way out is to narrow its role: manual review belongs in rubric design and calibration, and in exception workflows for scores that trigger an alert. The production pipeline shouldn’t need it.
Reframe: the scoring contract is customer understanding
Shifting from rep behaviour to buyer understanding changes which questions the rubric asks. Instead of "did the rep ask open-ended questions", the question is "did the buyer articulate a quantifiable business problem with a stated cost or consequence." Instead of "did the rep cover the key differentiators", the question is "did the buyer describe the gap between where they are and where they need to be."
These questions are answerable from evidence in the transcript, which is the requirement that makes structured scoring possible. An AI model can’t reliably tell you whether the rep was "engaging", but it can reliably tell you whether the buyer used language that described a quantifiable pain. The first is a subjective quality assessment, and the second is a pattern-matching task against observable evidence, and the same pattern on the same transcript produces the same result on two separate runs.
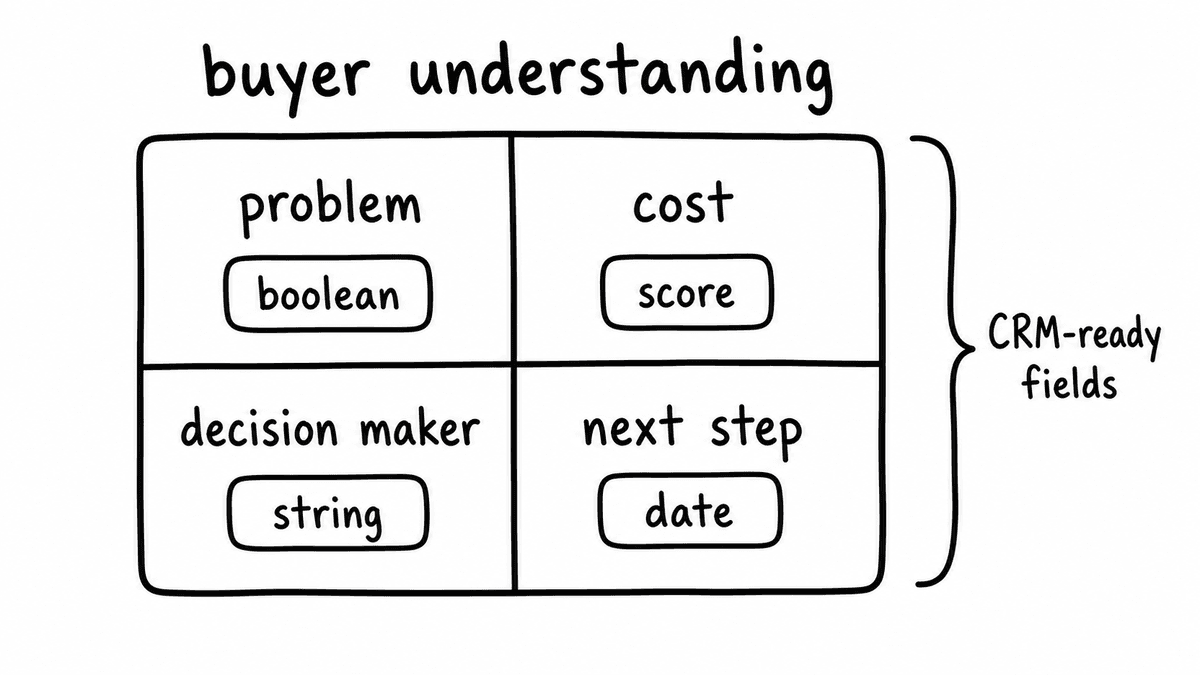
Four buyer-side criteria make a strong starting rubric: did the buyer articulate a quantifiable problem, did they describe the cost of not solving it, did they name a decision maker or budget holder, and did they commit to a specific next step with a date or owner. These four fields are consistently correlated with deal progression and consistently extractable from transcript evidence. Once they are wired into CRM, the schema can expand to include risk flags, competitive mentions, and framework-specific elements like MEDDIC qualification criteria.
Building the rubric with Bricks
In Semarize, each rubric criterion is a Brick: a single typed evaluation unit that the API applies to a transcript and returns a concrete value for. A Brick is a boolean, a score on a defined scale, an extracted string, or a categorical flag. The specificity requirement is the same for all types: the question must be answerable from evidence in the transcript, and the same transcript must produce the same answer on two separate runs.
"Did the buyer name the person who controls the budget decision?" is a boolean Brick. "Did the buyer describe the specific gap between where they are and where they want to be?" is a boolean Brick for implicated pain. Each returns a typed value the CRM field or reporting model can consume directly, with no interpretation step between the model output and the destination field.
Kits group related Bricks into versioned evaluation schemas. A discovery Kit and a QA Kit can be applied to the same call and return separate, structured outputs for each purpose. Versioning means scores from different periods remain comparable as long as the Kit version is consistent, and when the scoring logic changes, historical calls can be rescored for comparison rather than silently inheriting the new criteria.
From transcript to CRM: the pipeline
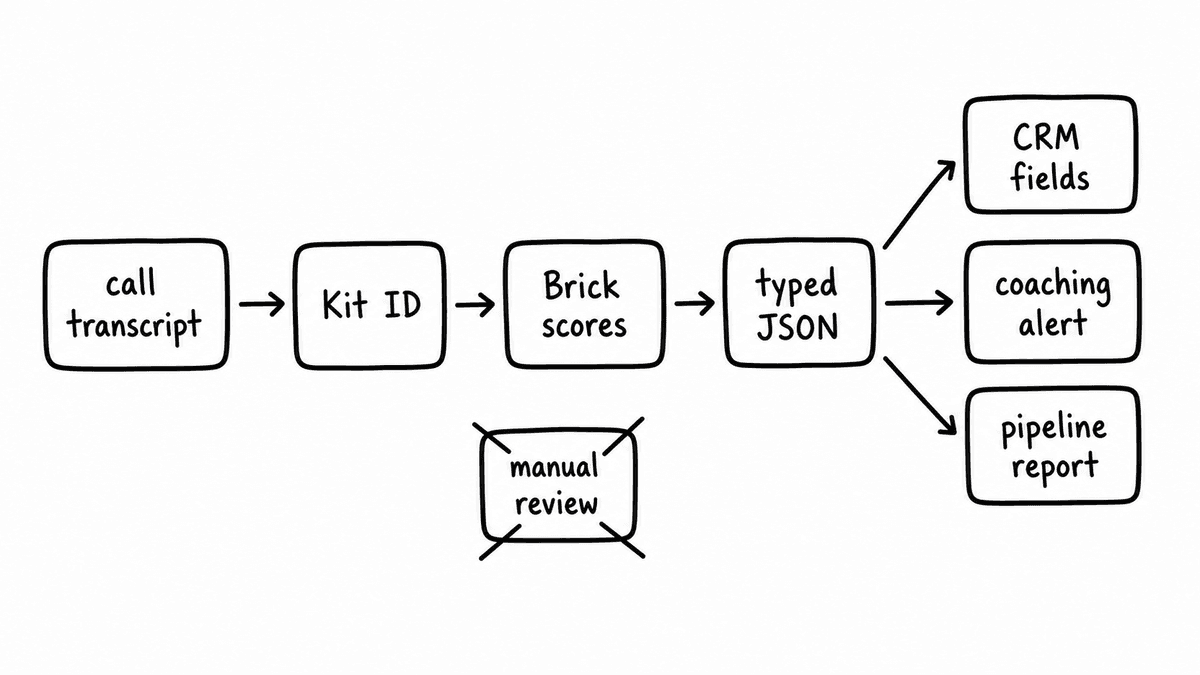
The workflow has three steps. The transcript arrives via webhook from a recording platform like Gong, Fathom, or Fireflies after a call ends, or via direct upload for teams ingesting from Zoom, Teams, or another source. The transcript is sent to the Semarize API with the Kit ID that defines the scoring schema, and the API evaluates every Brick in the Kit against the transcript, returning a structured JSON object with one typed field per Brick. The scored fields are then written to the CRM, the data warehouse, or the coaching dashboard, either directly via the CRM API or through an automation layer in Make or n8n.
No manual review step in the production loop means the pipeline scores every call automatically and returns consistent structured output within seconds of the call ending. A team sampling ten percent of calls for manual QA covers ten percent of calls with significant reviewer time and selection bias in which calls get reviewed. The 100% QA scoring post covers what this looks like for compliance-heavy environments.
Pushing scored results into coaching and CRM
The value of structured scoring data comes from routing it into the systems where coaching decisions are made. For CRM enrichment, this means writing Brick scores to opportunity fields in Salesforce or HubSpot after each call, so the deal record reflects what actually happened in the conversation. A discovery quality score on an opportunity record lets a sales manager see which deals have documented buyer pain and which don’t, without listening to a single call. The CRM enrichment playbook covers the field mapping and automation patterns in detail.
For coaching, scored fields from every call give a manager a factual basis for rep-level analysis: where discovery quality drops across the funnel, how often a particular rep scores below threshold on buyer commitment signals, which call types show the widest gap between top and bottom performers. These analyses are possible because the scores are typed, comparable, and complete across every call in the dataset, not sampled and not dependent on which calls a reviewer happened to select. Coaching grounded in buyer understanding signals across the full call set produces a different category of insight than coaching grounded in the calls that stood out to a listener.
Map each Brick to a CRM field before the first call goes through the pipeline, decide whether the field updates on every call or only on the first call that returns a positive signal, and set thresholds for coaching alerts. If a discovery quality Brick falls below a defined score after a Stage 2 call, the right output is a Slack notification or a CRM task for the manager. The integration is where scoring stops being a reporting exercise and starts changing behaviour.
Semarize scores every call automatically against your rubric and returns typed JSON fields ready for CRM enrichment, coaching workflows, and pipeline reporting.
Common questions
What rubric fields should we start with to measure buyer understanding?
Start with four: did the buyer articulate a quantifiable business problem, did they describe the cost or consequence of not solving it, did they name a decision maker or budget holder, and did they commit to a specific next step with a date or owner. These are the fields most consistently correlated with deal progression and most consistently answerable from transcript evidence. Once they are wired into CRM, the schema can expand to include risk flags, competitive mentions, and framework-specific criteria like MEDDIC elements.
How do we avoid theatre scorecards when the model is accurate but not useful?
Run a retrospective: take a set of closed-won and closed-lost deals and check whether your Brick scores are differentiated between the two groups. If they aren’t, the criteria are measuring rep behaviour proxies rather than buyer signals. The test for a useful scoring system isn’t whether the model is accurate, it’s whether the scores predict an outcome you care about. Accurate but undifferentiated means the rubric is measuring the wrong subject, and the fix is to redesign the criteria around what the buyer said and understood.
Do we need manual review at all?
Manual review has a role in rubric design and calibration, not in the production scoring loop. When defining new Bricks, reviewing a sample of calls against the criteria manually helps validate that the Brick answers the right question and returns consistent values. Once the rubric is validated, the production pipeline shouldn’t require review for every call. Reserve it for exception workflows where a score triggers an alert, or where a rep disputes a coaching decision, rather than using it as a systematic trust mechanism for every output.
Can the same rubric work across calls, meetings, and chats?
Yes, with some adaptation. The underlying questions are often the same: did the buyer articulate a problem, confirm a next step, name a decision maker? What changes is the evidence pattern in the transcript. Discovery calls tend to produce the clearest evidence for these criteria. Follow-up calls and email threads may contain thinner evidence for some Bricks, which the scoring engine handles by returning null or low confidence rather than guessing. Designing your Bricks to handle partial evidence explicitly produces more useful data than criteria that force a binary result regardless of what the transcript contains.
How should we integrate scoring results into CRM workflows?
Map each Brick to a CRM field before the first call runs through the pipeline. Decide whether the field updates on every call or only on the first call that returns a positive signal, and set thresholds for coaching alerts: if a discovery quality Brick falls below a defined score after a Stage 2 call, trigger a Slack notification or a CRM task for the manager. The CRM integration is where scoring stops being a reporting exercise and starts changing behaviour, and that shift depends on field mapping and threshold logic being defined before the pipeline goes live.
Continue reading
Read more from Semarize
100% QA Scoring Without Manual Review: Deterministic Rubrics for Every Call
Manual QA sampling at 2–5% has two problems: coverage and consistency. Automated scoring with deterministic rubrics solves both - every call gets scored the same way, with no reviewer required to generate the result. The shift isn't just efficiency - it changes what coaching is built from and turns compliance verification from sampling into complete coverage.
Bricks and Kits: the mechanism for stable conversation evaluation
Freeform prompts produce inconsistent evaluation results - scores drift, output shapes change, and you can't tell whether coaching improved anything or whether the rubric moved. Bricks define a locked evaluation schema: one question, one output type. Kits group them into reusable evaluation workflows. The result is schema-stable conversation analysis you control.
AI Scorecards Don't Disagree. Your Prompt Does.
Inconsistent AI scorecards aren't an AI problem - they're a process failure. Freeform prompts ask the model to re-interpret evaluation criteria on every run, and that interpretation drifts with phrasing, model updates, and context. The fix is an evaluation contract: a locked schema with defined output types that produces the same result on the same call, every time.