Conversational Intelligence API vs AI Note-Taker: What Changes?
A call ends. Both an AI note-taker and a conversational intelligence API can process what was said - but what comes back is different in kind, not just degree. One produces a document for a person to read. The other produces a data record for a system to consume. That distinction, not model quality or transcript accuracy, is what determines what you can actually build with the output.
Both categories are useful. A note-taker is built for individual review and does that job well. A conversational intelligence API is built for data infrastructure - CRM enrichment, automated scoring, cross-call reporting, and downstream workflows that run without a human reading step in between. Neither is a more advanced version of the other. They serve different jobs.
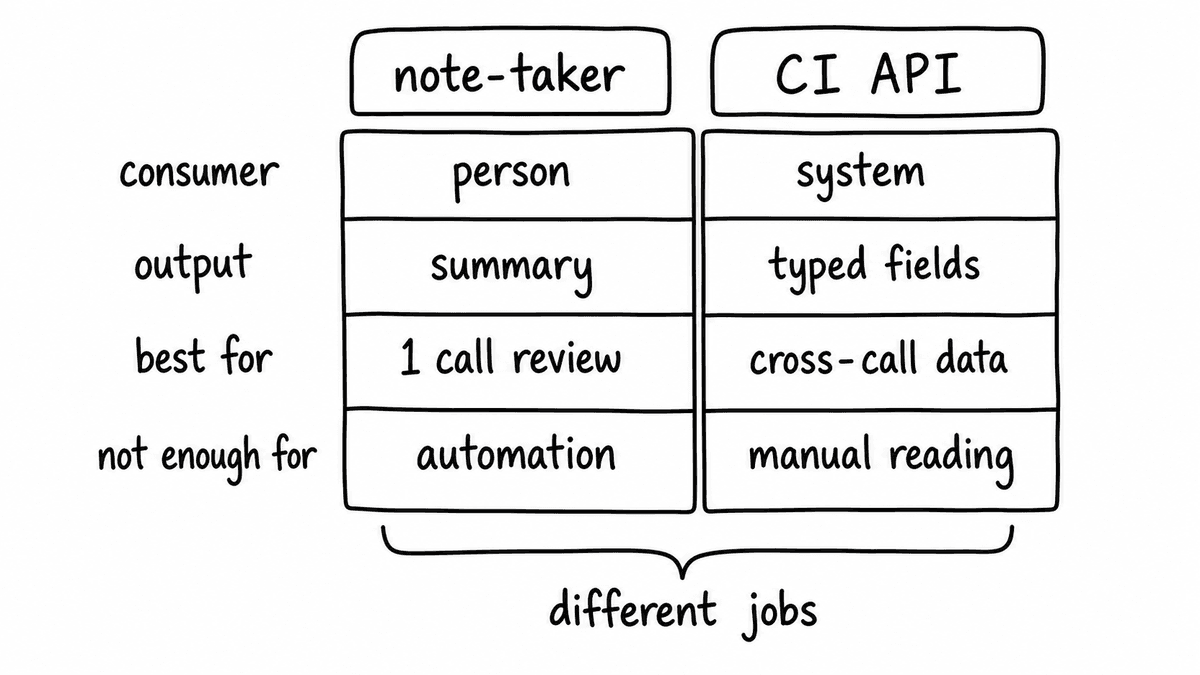
Output format
An AI note-taker returns prose. After the call: a summary paragraph, action items, a transcript on record. The format is designed to be readable, and for that job it works. A person opens the summary, reads it, and decides what to do next.
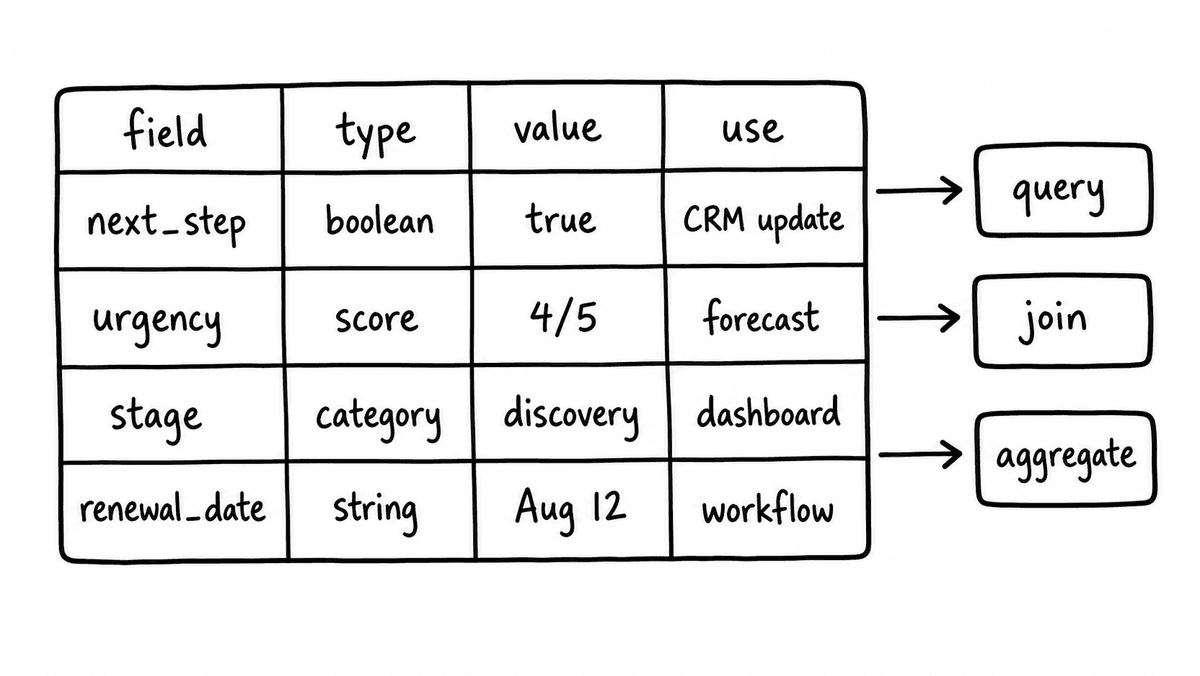
A conversational intelligence API returns typed fields. next_step_confirmed: true, discovery_depth: 74, competitor_mentioned: "Salesforce", churn_risk: "elevated". Each field has a defined type - yes/no, score, category, extracted text - and arrives in the same shape every time. No prose to interpret. The output is a data record.
This is fixed at the design level. A note-taker can't be configured to return typed fields; a CI API doesn't produce prose summaries. These aren't settings - they reflect what each product is built to do.
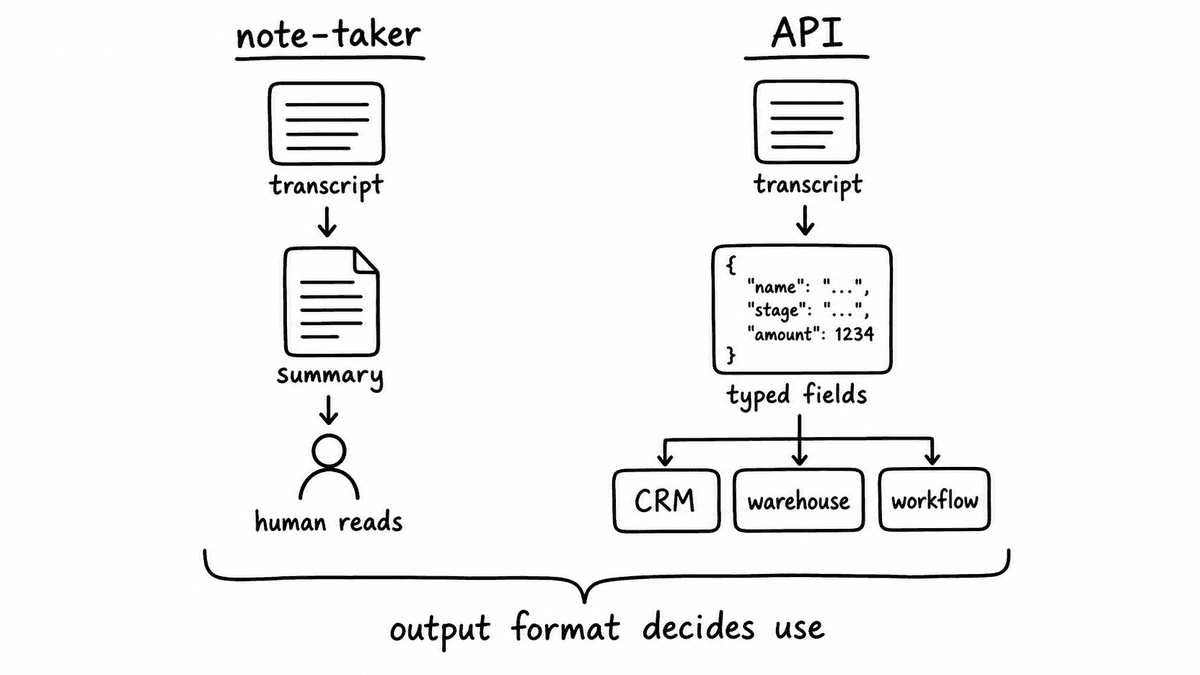
Primary user
A note-taker's primary user is a person. A rep reviewing their own call. A manager preparing for a coaching session. A CS lead checking what was discussed before a renewal. The document lands in an inbox or activity feed, and a human decides what to do next. The intelligence stays inside the document until someone reads it.
A conversational intelligence API's primary user is a system. A CRM waiting for a field update. A dashboard pulling qualification scores. An alerting workflow watching for churn signals. A BI tool aggregating call data alongside pipeline records. No human reads the output before it's used - and that's the point.
Downstream use
A note-taker's downstream use depends on a manual step. Someone reads the summary and decides whether to update an opportunity stage, send a follow-up, or flag a risk. The intelligence is in the document; action follows from a person interpreting it. That model works when individual review is the job.
A conversational intelligence API's downstream use is direct integration. Structured fields write to CRM without a rep touching the record. Scores feed a performance dashboard. Risk flags trigger a CS workflow. Qualification data populates a pipeline report. The RevOps and GTM engineering workflows that depend on this - CRM field enrichment, real-time qualification scoring, automated rep performance dashboards, churn risk indicators from CS calls- all require structured data and can't be built on prose summaries.
Automation readiness
Prose summaries are difficult to automate from reliably. You can build extraction logic on top of them - parse the text, look for keywords, try to infer a yes/no value from a sentence. This works for simple cases and breaks down as the evaluation logic gets more nuanced, because the source material is prose written for a different purpose rather than structured output designed for extraction. It's a workaround for the absence of structured data rather than a solution.
Structured data is automation-ready by design. A CRM automation triggered by next_step_confirmed: false doesn't need to parse any text. A qualification workflow that checks discovery_depth < 60doesn't need a language model to interpret a paragraph. The field is there, it has a type, and the downstream system acts on it immediately.
Reporting and queryability
Cross-call reporting on prose summaries requires reading every summary or building extraction on top of them after the fact. Trending qualification scores, comparing objection patterns by rep, measuring whether training has shifted behaviours in the field - none of these can be answered from a folder of call notes without significant manual work.
Structured conversation data is queryable from the start. The same fields, extracted the same way, from every call. Filter by score range, group by rep, join to pipeline records, trend over time. A question like “what percentage of discovery calls hit a qualification depth above 70 last quarter?” becomes a database query rather than a reading project.
When a note-taker is enough
When individual review is the job. A rep preparing for a follow-up. A manager reading through recent conversations before a 1:1. A CS lead checking what was discussed before a renewal. These workflows have a person in the loop who reads the output, makes a judgment, and acts. The document is the right format for that job, and note-takers do it well.
Note-takers are also useful alongside a conversational intelligence API. Many teams run both: a note-taking tool for individual rep review and coaching, and a CI API for the structured data layer that feeds CRM, reporting, and automation. They serve different layers of the same process and aren't in competition.
When a conversational intelligence API is needed
When the downstream consumer of conversation output is a system. CRM enrichment that updates automatically after every call. Rep performance dashboards built on signals from every conversation. Qualification scoring written to pipeline records in real time. Churn risk indicators surfaced before a renewal conversation happens.
When cross-call reporting is the goal. Any question that requires aggregating signals across hundreds of conversations - qualification depth by rep, objection frequency by product, coaching lift over time - needs the same fields extracted the same way from every call. And for QA programmes that need 100% call coverage rather than a sampled review, structured output is the only model that scales.
How Semarize works: Bricks and Kits
In the Semarize conversational intelligence API, the evaluation logic lives in Bricks and Kits. A Brick is a single typed evaluation criterion - the question you want answered about the conversation and the format the answer should take: yes/no, a score out of 100, a category from a defined list, or an extracted string pulled directly from the transcript. A Kit is a versioned group of Bricks assembled into a complete evaluation schema for a specific use case - a discovery call qualification framework, a MEDDIC rubric, a CS health check.
Send the transcript to the API with a Kit ID. What comes back is a JSON object with one typed field per Brick - value, confidence, and the transcript quotes that support the answer. Store it in a database, write it to a CRM, feed it into a dashboard, trigger a workflow, join it to pipeline data for reporting. No prose to parse. No human reading step. The output behaves like any other structured record in your stack.
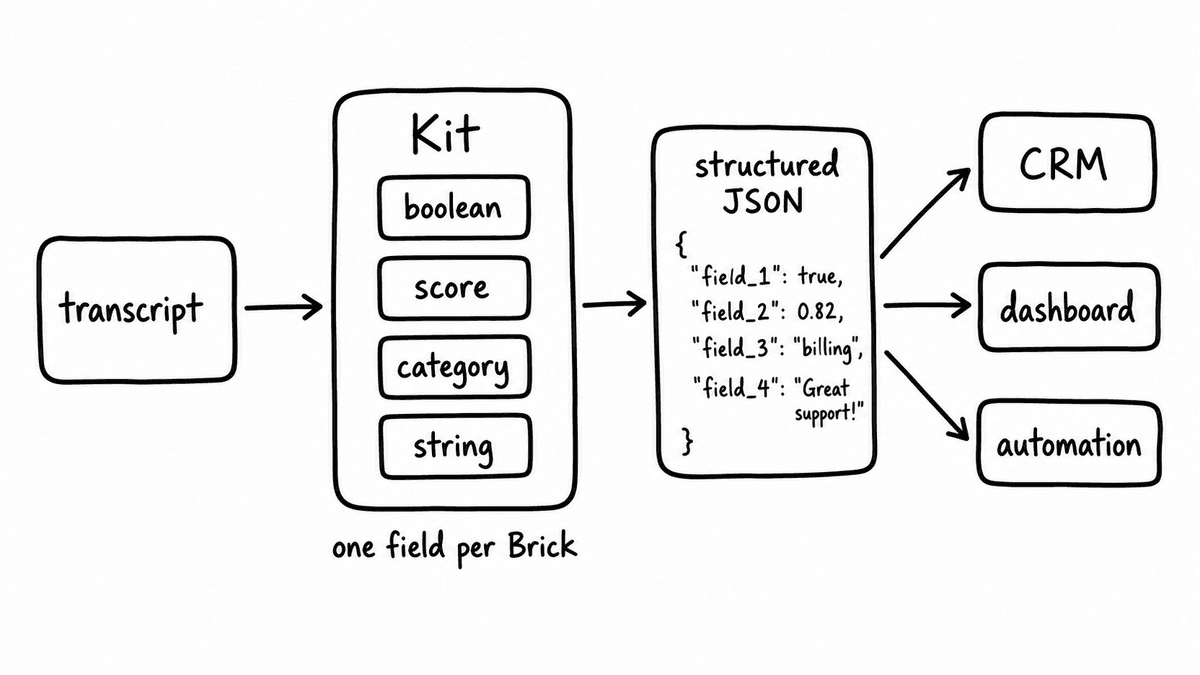
The recording and transcript layer stays whatever it already is. The API sits between the transcript and the rest of your stack, converting unstructured conversation content into structured signals that downstream systems understand natively.
The dedicated conversational intelligence API from Semarize turns every conversation into typed fields, scores, and evidence-backed JSON - ready for the rest of your stack without a reading step in between.
Common questions
What is the difference between a conversational intelligence API and an AI note-taker?
An AI note-taker generates prose summaries, action items, and call notes designed for a human to read and act on manually. A conversational intelligence API returns typed, structured data - scores, yes/no fields, categories, and extracted strings formatted as JSON that downstream systems can store, query, and act on directly. The primary consumer of a note-taker's output is a person; the primary consumer of a conversational intelligence API's output is a system, and that determines what each product can and can't be used to build.
What does structured conversation data actually look like?
It's a JSON object with typed fields corresponding to the evaluation criteria in your schema. A field might record whether the rep confirmed a specific next step (yes/no), how clearly the buyer articulated urgency on a numeric scale, which qualification stage the call focused on (category), or the exact renewal date the buyer mentioned (extracted text). Each field has a name, a type, and a value, and the object as a whole behaves like any other record in a relational or document database - filterable, joinable, and aggregatable across many records.
Can a conversational intelligence API work alongside an existing recording platform?
Yes - the API receives conversation content as a transcript and doesn't require a specific recording source. Teams typically send transcripts from their existing platform to the API and route the structured outputs downstream to CRM, reporting tools, or automation workflows. The recording layer and the intelligence layer stay separate, so adding structured signal extraction doesn't require replacing the tools already in use for recording or call review.
What are Bricks and Kits in Semarize?
A Brick is a single typed evaluation criterion - the specific question you want answered about a conversation and the format the answer should take. A Kit is a versioned group of Bricks assembled into a complete evaluation schema for a given use case, such as a discovery call qualification rubric or a MEDDIC scoring framework. Sending a conversation to the API with a Kit ID returns a structured JSON object with one typed field per Brick, ready to be used by any downstream system.
Which teams benefit most from a conversational intelligence API?
Teams that need to aggregate, automate, or report across large volumes of conversation data: RevOps leads maintaining CRM data quality, GTM engineers building performance dashboards and enrichment workflows, and sales enablement managers running QA programmes at 100% call coverage. For individual call review and coaching, a note-taker serves that job well. For automated processing, cross-call reporting, or integration with downstream systems, structured API output is the right model.
Continue reading
Read more from Semarize
What is a Conversational Intelligence API?
Conversational intelligence gets applied to three very different things - deal intelligence, note-taking, and pattern-level analysis. Only one produces data your systems can act on. Here's what a CI API actually does and how the shift away from full-platform solutions is changing what's possible.
How to Turn Your Note-Taker Into a Serious Sales Enablement Source
Most sales teams have transcripts from every call they've ever recorded. Almost none of them are using that data for coaching analytics, CRM enrichment, or QA at scale. The gap isn't the recording - it's the extraction layer that turns transcripts into structured signals.
Conversation Intelligence for Developers: Don't Build a Fragile Pipeline, Don't Buy a Black Box
Most teams don't fail to add conversation intelligence because the model is bad; they fail because the integration is fragile and unstructured. The fix isn't a better LLM pipeline or a platform API you can't control. It's a layer that takes a transcript, runs it against a versioned Kit, and returns deterministic typed JSON you can test, version, and route into your product.