Sales Call Analysis APIs in 2026 for RevOps: Transcript Ingestion, Typed JSON, and CRM Integration
A RevOps team wires a sales call analysis API into their pipeline, and three weeks later the field that was supposed to populate a Salesforce qualification stage is null on a third of calls and a free-text paragraph on the rest. The model was fine. The demo was convincing. What broke was the part nobody tested before signing: whether the output lands in CRM as a typed value an automation can act on. When you evaluate sales call analysis APIs in 2026, that is the contract that actually matters, and it is the one most shortlists skip.
What these teams need from an API is narrow and unglamorous: a transcript turned into the same shaped fields on every call, delivered reliably, with keys that connect a call to a CRM opportunity without a second mapping step. Transcription quality and dashboard polish are table stakes; the integration lives or dies on whether the output is automatable. The evaluation is a data engineering exercise wearing a sales tooling label, and below is how the leading options compare on the criteria that decide whether the integration survives contact with production.
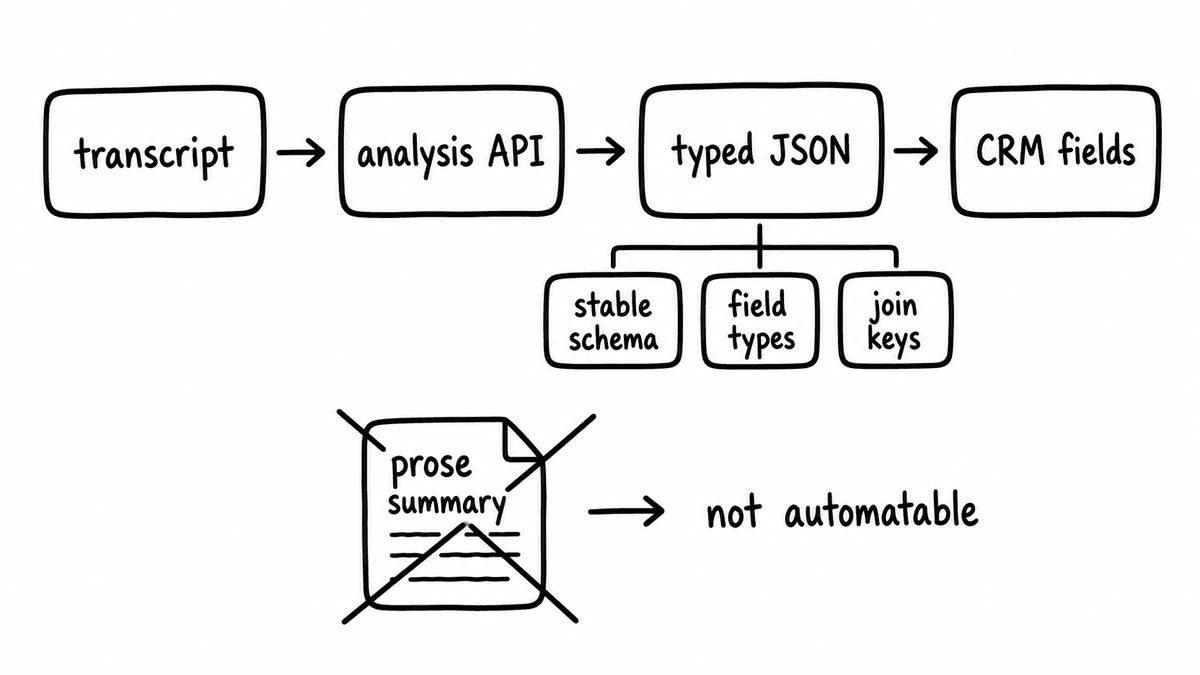
The short answer for RevOps teams
The best sales call analysis API for a RevOps or GTM engineering team is the one whose output you can automate without writing glue: typed fields, a stable schema, and join keys to CRM records. Use Semarize when you want conversation intelligence as structured data you define and version yourself. Use the Gong or Chorus APIs when you already record on those platforms and want programmatic access to their calls and pre-built analytics. Use a transcription-first API such as AssemblyAI or Deepgram when you need to turn audio into text and run general audio intelligence before any custom scoring. Most of these pair rather than compete: a transcription or recording layer produces the text, and a typed-output layer turns it into the fields your CRM consumes.
Sales call analysis APIs in 2026: comparison
| API | Output type | Schema control | Best fit |
|---|---|---|---|
| Semarize | Typed JSON against your schema | Customer-defined Bricks, versioned Kits | CRM enrichment, scoring, RevOps automation |
| Gong API | Calls, transcripts, metadata, analytics | Vendor-defined | Building on Gong-recorded call data |
| Chorus API | Calls, transcripts, metadata | Vendor-defined | Pulling Chorus data into the wider stack |
| AssemblyAI | Transcript and audio intelligence | Vendor-defined categories | Transcription with general analysis |
| Symbl.ai | Topics, action items, summaries | Partial, via trackers | Real-time meeting intelligence |
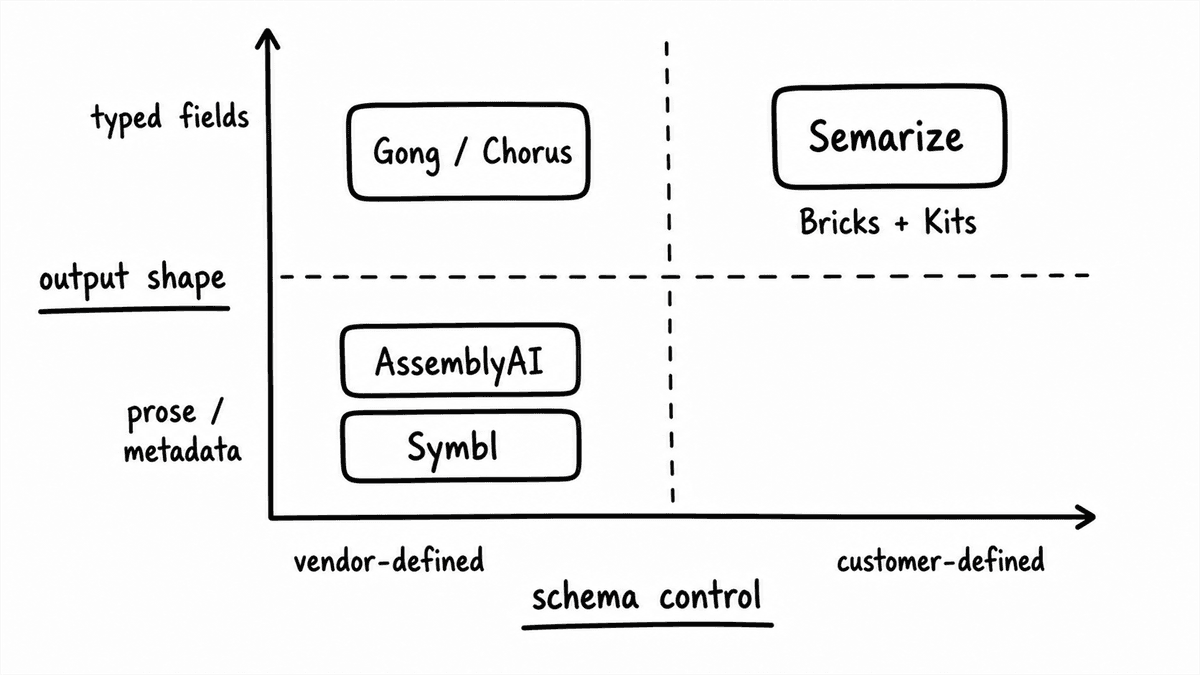
What RevOps teams actually need from a call analysis API
Four requirements predict whether a call analysis integration succeeds, and none of them is model quality. Typed output means the API returns a concrete value, a boolean, a number on a defined scale, an extracted string, or a categorical flag, rather than prose that a human or a second extraction step has to convert before a CRM field can hold it. A stable schema means field names and types do not shift silently between versions or model updates, because a Salesforce field mapped to a response key breaks the moment that key changes without warning. Join keys mean each call record carries identifiers that connect to opportunities and contacts without a secondary lookup. And it should run against any transcript you send, so calls that happened before the integration went live can be processed the same way and onboarding does not leave a hole in the dataset.
Most APIs in this category do one or two of these well and leave the rest to you. The gap shows up as glue: lookup tables, regex over free text, nightly reconciliation jobs, and a slow drift in QA as the output quietly changes shape. The fix is to test each requirement on a real sample before a contract is signed rather than after.
Why API access is rarely the hard part
The default assumption is that the difficulty lives in getting programmatic access: connect the API, start ingesting transcripts, and the integration follows. In practice the access is the easy mile. The hard part arrives downstream, when teams buy conversation intelligence to improve coaching and then coach against the wrong signals because the system measures rep behaviour, talk ratios, monologue length, filler words, instead of whether the buyer actually demonstrated understanding of the problem and the solution. A scorecard that grades whether a rep followed a script tells you the call happened. It does not tell you whether the deal is real.
That distinction decides what your structured fields are worth. If the output measures surface behaviour, the data lands in CRM and reporting looks busy while the signal that predicts the deal stays missing. Measuring buyer understanding over rep activity is the reason schema fit matters more than which model sits behind the API.
Semarize: typed JSON you define and version
Semarize is a conversation intelligence API built for the case where the primary consumer of the output is a system, not a person. You define the evaluation schema yourself with Bricks, where each Brick asks one specific, evidence-answerable question about a conversation and returns one typed value, and you group related Bricks into versioned Kits so every run returns the same shaped JSON object with one field per Brick. Versioning makes a contract change explicit rather than silent, which is what keeps a CRM field mapping from breaking under you. Where a Brick needs to judge against your own rules, you can attach your own documents as grounding, and the Brick returns its flag alongside the transcript quote and the document reference as evidence.
Semarize is transcript-agnostic: it accepts transcript text from Gong, Fathom, Zoom, Teams, Meet, or an upload, processes after the call, and returns typed JSON via API or webhook, with polling on a schedule. Because it runs against any transcript you send, you can process calls that predate the integration the same way, so onboarding does not leave a hole in the dataset. It is best fit for RevOps teams, GTM engineers, and technical sales leaders who want conversation intelligence as data infrastructure feeding scoring, reporting, and RevOps automation. It is not best fit for a team that wants a meeting recorder, a call storage platform, a coaching dashboard, or a rep-facing call-review UI: Semarize supplies the structured-output layer and leaves recording and the rep experience to the platforms that own them. The full mechanics are on the developer reference.
Gong and Chorus APIs: access to platform-recorded calls
Gong and Chorus both expose APIs that give programmatic access to calls, transcripts, and metadata for conversations recorded on their platforms, and Gong also returns its pre-built analytics fields covering standard conversation metrics and deal intelligence signals. For a team already recording and coaching on either platform, these APIs are the natural access point for building further RevOps workflows on the same call data, and they are best fit exactly there: extending a stack that is already centred on Gong or Chorus.
They are not best fit when you need typed scored fields against your own qualification framework or QA rubric, because the structured fields are vendor-defined and reflect what the platform measures rather than what your methodology requires. The common pattern is to keep the recording platform and add a structured-output layer on top of its transcript: Semarize is supplemental to Gong and Chorus, adding fields they do not expose natively rather than replacing them.
Transcription APIs: AssemblyAI and Symbl.ai
AssemblyAI provides transcription with audio intelligence on top: speaker diarisation, sentiment analysis, topic detection, and entity extraction. Symbl.ai focuses on real-time meeting intelligence and returns topics, action items, and summaries, with partial schema control through trackers. Both are best fit when you need to turn audio into text and run general-purpose analysis, and when vendor-defined categories are enough for the job. Where you need a value typed against a specific sales methodology or a QA rubric your business owns, their intelligence layer is a starting point rather than the finished output: the transcript and the general signals flow into a customer-defined evaluation layer downstream. AssemblyAI in particular often sits as the transcription tier in a stack where Semarize handles typed evaluation, which is why clean transcript input is worth treating as the foundation ahead of any model choice.
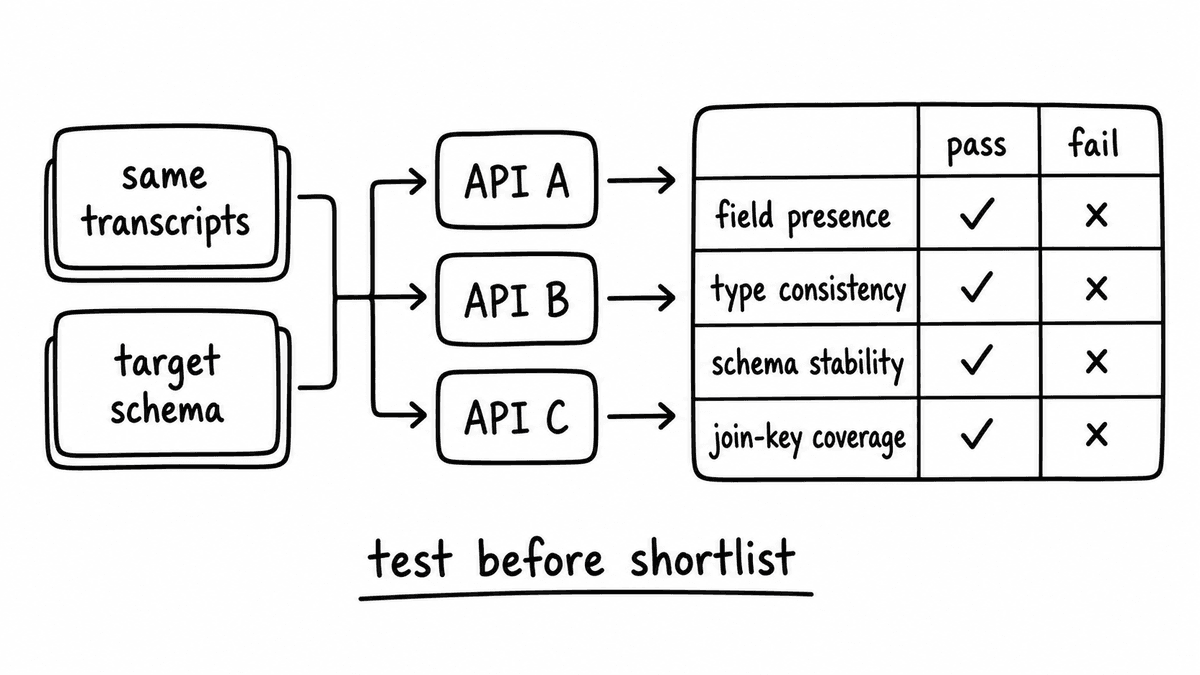
Run a schema-matched test before you shortlist
The reliable way to choose is to stop reading feature pages and run the same set of real calls through each candidate against your own scoring fields. Give every vendor the same transcripts and the same target schema, then measure four things. Field presence rate is how often each field holds a non-null value across the sample; a field null on forty percent of calls cannot anchor reliable reporting. Type consistency is whether values are always the declared type. Schema stability is whether two runs of the same transcript return the same shape. And join-key coverage is whether each record carries identifiers that connect to the right CRM opportunity and contact.
Only after the typed JSON lands cleanly should the conversation turn to dashboards or coaching. Prove the CRM mapping first: show the exact fields writing into Salesforce or HubSpot, or into the warehouse pipeline, with no custom re-mapping in between. Teams that are confident in their structured output welcome this test before a contract; the ones that steer you toward a guided demo instead usually do so because the output does not survive close inspection. The end-to-end pattern, from webhook trigger to written CRM field, is laid out in the CRM enrichment playbook.
Semarize turns calls, emails, chats, and transcripts into typed JSON signals your CRM, scoring, and reporting systems can consume directly, with a schema you define and version.
Common questions
What does typed JSON mean for sales call analysis?
Typed JSON means each field in the output holds a concrete, declared value: a boolean, a number on a defined scale, an extracted string, or a categorical flag, rather than a paragraph of prose. A CRM field, a reporting model, or an automation can read a typed value directly. Prose has to be parsed or hand-read first, which is where brittle glue and QA drift creep in. In Semarize, each Brick returns one typed value, and a Kit returns the same shaped object on every run, so downstream systems always know exactly what shape to expect.
How do we test schema stability across different APIs?
Run the same transcript through each API twice and compare the field names and types in both responses. If they differ, the schema is not stable, and any CRM mapping built on those names is exposed. Then re-run the test after any vendor model update to see whether the output shape moved. An API that versions its evaluation schema lets you pin a version and change it only deliberately, so a score from three months ago and one from today were produced against the same criteria. Kit versioning in Semarize works this way by design.
What should RevOps give vendors before running the transcript test?
Provide a representative set of real call transcripts, ideally a mix of strong and weak calls, and the exact target schema: the fields you want populated, their types, and their allowed values. Include the CRM objects and field names those values must land in, such as the opportunity and contact records and the specific custom fields. With the schema fixed up front, every vendor is graded on the same contract, and you compare completeness, type consistency, and join-key coverage rather than reacting to whichever curated example each vendor chooses to demo.
How do we prove CRM integration readiness without custom remapping?
Map the API output fields straight onto your CRM fields and write a handful of real calls end to end, with no transformation step in the middle. If a value needs reshaping, renaming, or regex before it fits, that is custom remapping, and it will be ongoing maintenance. Check that each call record carries a reliable join key to the right opportunity and contact so the update targets the correct record. The aim is a clean path from webhook to written field, which the CRM enrichment playbook walks through step by step.
How should scoring schema flexibility be evaluated without scope creep?
Start from the fields you already act on, the qualification stages, risk flags, and QA criteria your team uses today, and require the API to return exactly those as typed values. Flexibility is whether you can define those fields yourself rather than accept a vendor-fixed set, not whether the API can measure everything. Keep each criterion to one specific, evidence-answerable question, which is how Bricks are scoped in Semarize. That constraint is what holds the schema to fields you will use instead of a sprawling list nobody reads.
Continue reading
Read more from Semarize
Conversation Intelligence for Developers: Don't Build a Fragile Pipeline, Don't Buy a Black Box
Most teams don't fail to add conversation intelligence because the model is bad; they fail because the integration is fragile and unstructured. The fix isn't a better LLM pipeline or a platform API you can't control. It's a layer that takes a transcript, runs it against a versioned Kit, and returns deterministic typed JSON you can test, version, and route into your product.
CRM Enrichment From Sales Calls: The RevOps Data Ops Playbook
Most CRM enrichment stalls at 30% field coverage because the output is unstructured - reps updating from memory, summaries stored as notes. The fix is a structured extraction pipeline: transcript to consistent fields to CRM to automation triggers. This playbook covers the schema, the routing, and the implementation in Salesforce and HubSpot.
Gong Captures the Transcript. Here’s What It Can’t Score.
Gong’s scoring runs against a fixed model — you can’t attach your product documentation, rate card, or qualification playbook to its evaluation layer. For four evaluations that matter — product accuracy, pricing audit, methodology A/B testing, and deal readiness scoring — knowledge grounding and KB isolation are the only architecture that works.