MEDDIC Without the Admin: Automated MEDDIC Scoring for Every Discovery Call
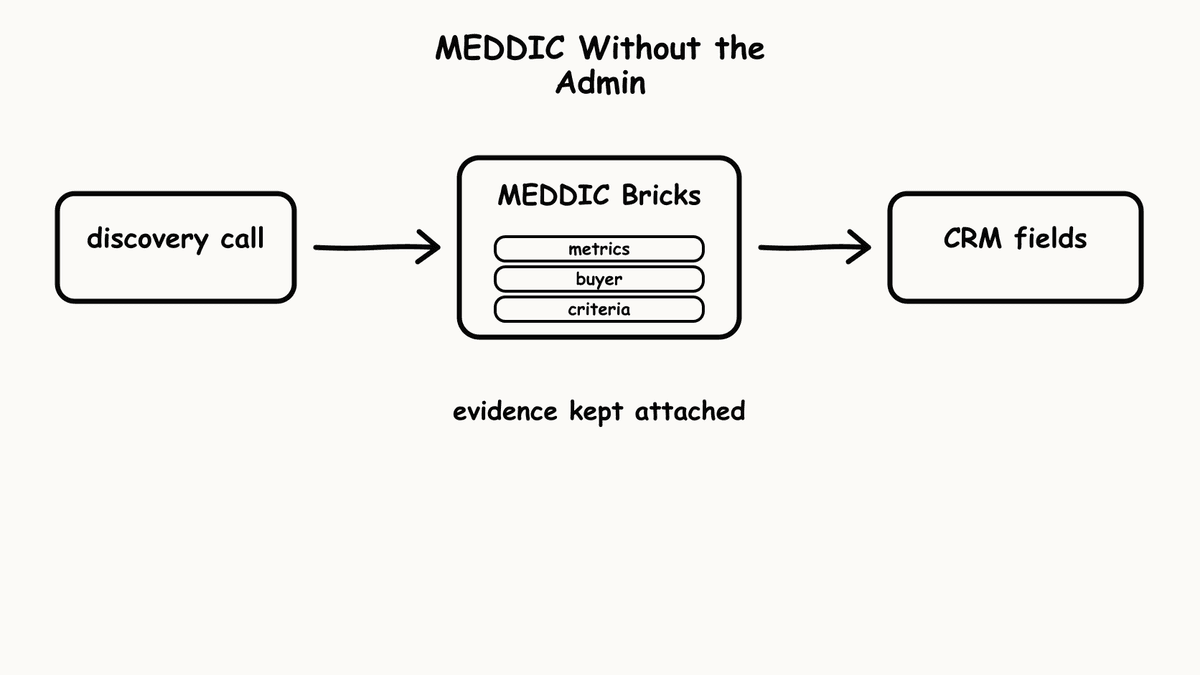
A discovery call wraps at 4:50pm, the rep has two more before end of day, and the MEDDIC fields on that opportunity stay exactly as they were: half empty, the rest filled in three weeks ago from memory. By Friday's pipeline review the deal is in Proposal, the Economic Buyer field still reads “procurement,” and nobody in the room can say whether the buyer ever named the person who signs off the budget. Automated MEDDIC scoring removes that gap by reading the transcript instead of waiting for the rep to remember. Each MEDDIC element becomes a single typed evaluation that runs after the call and writes back to the opportunity record without anyone touching a field.
MEDDIC is one of the most adopted qualification frameworks in enterprise software and one of the least reliably executed. The framework itself is sound: scoring deals against Metrics, Economic Buyer, Decision Criteria, Decision Process, Identify Pain, and Champion gives leaders a structured basis for forecasting, deal review, and coaching. What breaks is the data entry behind it. Reps complete the fields after calls, from recall, and update them when they get round to it, so the record ends up reflecting what a rep remembered and chose to type rather than what the buyer actually said.
The operational failure: MEDDIC fields built from memory
Walk into any weekly pipeline review and the symptom is the same. The MEDDIC fields are either blank or stale, and the conversation defaults to the rep narrating the deal from memory while the manager decides how much of that narration to believe. Metrics says “strong business case” with no number behind it. Champion is set to the friendly contact who answers emails quickly, not the person selling internally on the team's behalf. Decision Process is whatever the rep wrote down after the first call and never revisited, even though three more calls have happened since.
This is a measurement problem at root. Asking reps to be more diligent about updating qualification fields has been the standard fix for two decades and it has not worked, because the task competes with selling and selling wins. The data that ends up in the CRM is a function of which reps update records, when they remember to, and how generously they grade their own deals. Forecasts built on that data inherit every one of those distortions, and the teams that feel it most are the ones running deal inspection against fields that look complete but were never grounded in anything a buyer said.
What automated MEDDIC scoring actually changes
Automated MEDDIC scoring changes the data source. Instead of asking a rep to fill in a qualification field after a call, the system reads the transcript and evaluates whether each MEDDIC element was established in the conversation. The rep still owns the deal and runs the call; the system produces the evidence. The result is qualification data that reflects what was said, with coverage on every discovery call rather than the subset where the rep remembered to update the record.
The mechanism matters here, because automated does not have to mean a model writing a free text summary that someone still has to read and interpret. Semarize runs one Brick per MEDDIC element. A Brick asks one specific, evidence-answerable question about the conversation and returns one concrete typed value: a boolean, a score on a defined scale, an extracted string, or a categorical flag. It doesn’t summarise and it doesn’t produce prose. That distinction is the whole point. A typed value can be written to a Salesforce or HubSpot field, aggregated across a rep's call set, and trended over time. A paragraph of analysis cannot.
One Brick per MEDDIC element
The specificity of each Brick is what makes the output usable. The Metrics Brick doesn’t ask “did Metrics get discussed?” It asks whether the buyer articulated a measurable consequence of their current problem, stated as a financial cost, a time cost, or a quantified performance gap. The Economic Buyer Brick doesn’t ask “was the economic buyer identified?” It asks whether the buyer named the specific individual who controls the budget decision for this purchase. A vague criterion produces a score that means something slightly different every time it runs; a specific criterion produces a score that means exactly one thing, which is whether the evidence was present in this transcript.
Across the six elements, each Brick tests for a different concrete signal. Metrics looks for a stated number tied to the problem, so revenue impact, error rate, or headcount strain qualify while “it's really painful” doesn’t. Economic Buyer looks for a named decision-maker, so “the VP of Finance signs off anything above fifty thousand” qualifies while “it goes to procurement” doesn’t. Decision Criteria looks for the specific factors the buyer will judge solutions against, Decision Process looks for the sequence of steps and people involved in approving a purchase, Identify Pain looks for a problem with a cost and a timeline attached, and Champion looks for evidence that someone inside the account is actively selling internally rather than merely being friendly on calls. The deterministic MEDDICC scoring post covers the full criterion design for each element in detail.
The before and after process
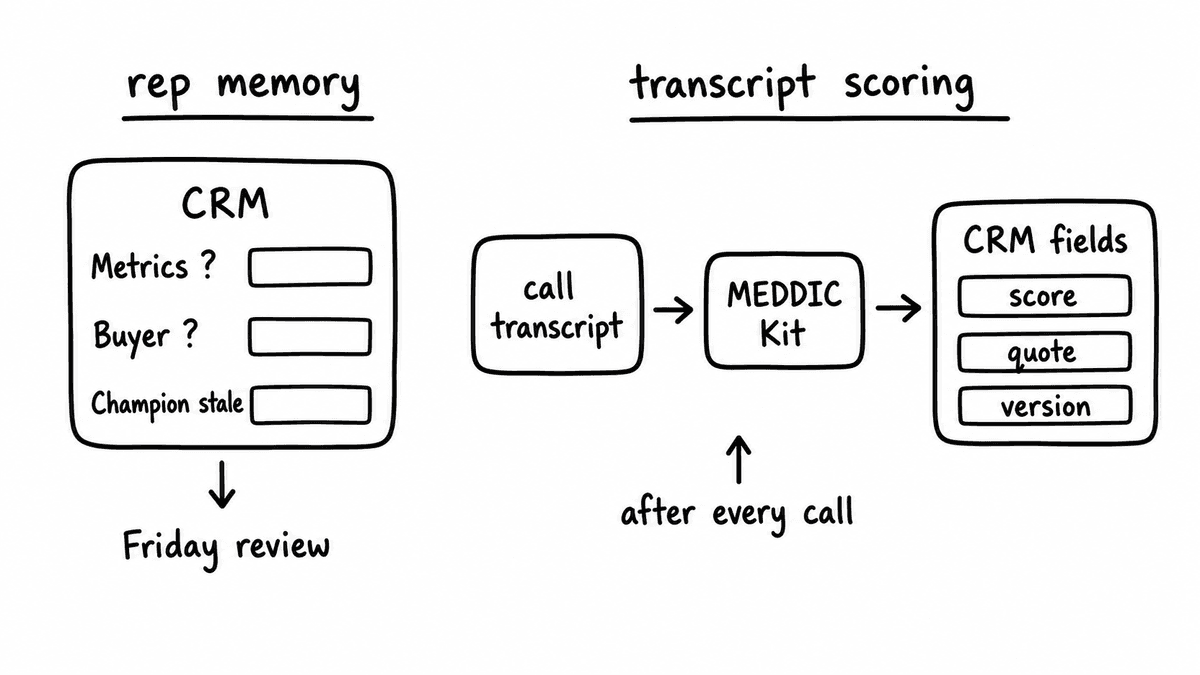
The before process runs on rep memory. A call happens, the rep moves on to the next one, and at some point before a forecast deadline the qualification fields get a pass based on whatever the rep recalls. Coverage is partial, timing is irregular, and the grading is self-reported, so the manager spends the review interrogating the data rather than the deal. The fields that look most complete are often the least trustworthy, because a confident rep fills them in fully whether or not the buyer said anything to support them.
The after process runs on transcripts. A call ends, the platform delivers the transcript, and a webhook triggers a Kit run. A Kit is a versioned schema that groups the six MEDDIC Bricks, and running it returns the same shaped JSON object on every run, with one typed field per Brick. The automation looks up the opportunity tied to the call and writes each score to its corresponding field. The reviewer now opens a record where the MEDDIC fields carry the result of the most recent conversation, and the question in the room shifts from “has this been established?” to “here is exactly what the buyer said, and here is the quote.” The framework runs on every discovery call, not the ones a rep had time to log.
The shape of the typed JSON output
Because a Kit returns a fixed object shape on every run, the downstream automation never has to parse prose to decide what to write. The MEDDIC Kit returns one field per element, each carrying a typed value: a score for metrics, a boolean for economic_buyer with the named decision-maker returned as evidence, a categorical flag for champion, and so on across the six. The same field maps to the same CRM property every time, which is what lets the automation stay a simple field write rather than a parsing exercise that breaks the first time the model phrases something differently.
Where the score depends on whether a conversation matched your own qualification rules rather than a generic definition, knowledge grounding attaches your own documents to the Kit so each Brick in it evaluates against your approved definition of, say, a qualified Economic Buyer. The Brick then returns the flag alongside the transcript quote and the grounding-document reference as evidence, so a manager can see not only the score but the exact line that produced it and the rule it was tested against. Versioning the Kit makes any change to those criteria explicit rather than silent, so a score from March is comparable to a score from June because you know which version produced each one.
Longitudinal scoring across the deal cycle
Running the MEDDIC Kit against every call in a deal builds a longitudinal view of how qualification progresses, not just a single snapshot. A deal where Metrics was established in discovery but Economic Buyer was never confirmed across five later calls shows a specific gap. A deal where Champion engagement scored high early and dropped through the middle calls shows a specific risk. Neither pattern is visible from a one-time field that a rep set once and left, and neither is visible from a generic deal score that collapses six distinct signals into one number.
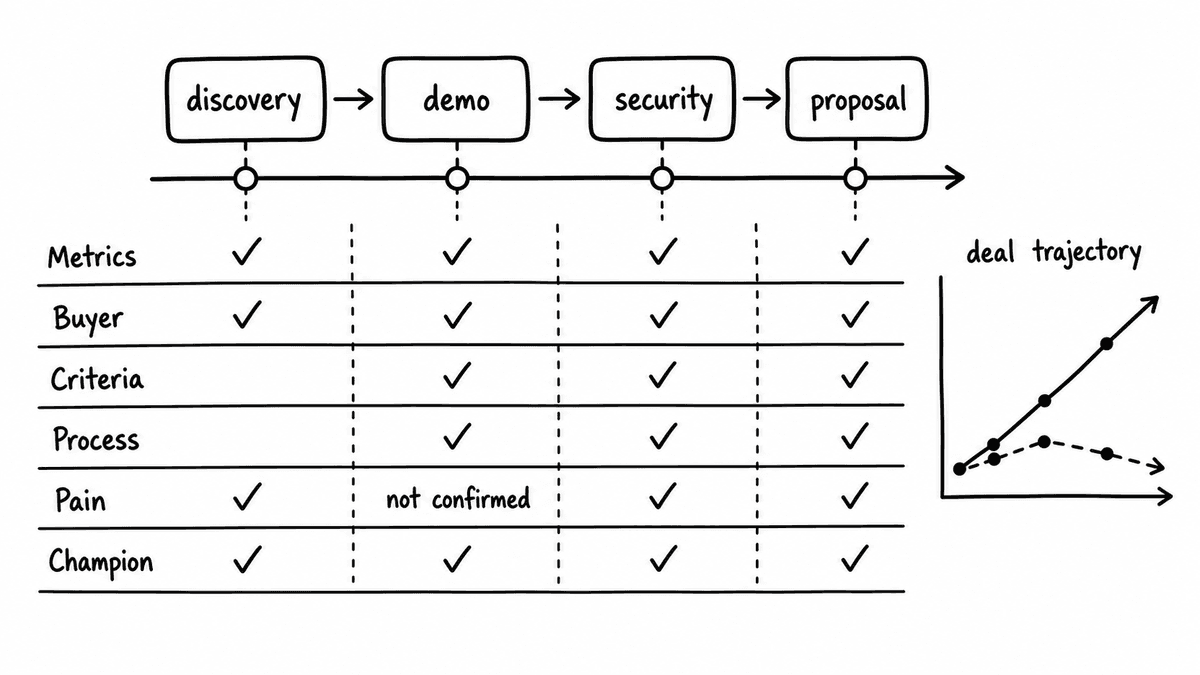
For RevOps teams running deal reviews and forecast models, MEDDIC scores that move across calls are more informative than static checkboxes, because the trend is evidence about deal trajectory rather than deal state. This is the same structured-data discipline that RevOps teams apply elsewhere, from CRM enrichment from calls to QA, and it distinguishes a pipeline that is genuinely qualified from one that looked qualified on its last manual update while quietly deteriorating for weeks.
Semarize turns every discovery call into typed MEDDIC scores and writes them straight to your CRM fields, so qualification data reflects what the buyer said and not what a rep remembered to enter.
Common questions
What is automated MEDDIC scoring?
Automated MEDDIC scoring evaluates a sales conversation against each MEDDIC element directly from the transcript, instead of relying on a rep to fill in qualification fields from memory after the call. With Semarize, one Brick handles each element and returns a typed value such as a score or a boolean, grouped into a Kit that produces the same JSON shape on every run. The scores write back to the CRM opportunity automatically, so every discovery call produces grounded, evidence-backed MEDDIC data rather than the partial, self-reported fields that manual entry leaves behind.
Does it work for MEDDICC and MEDDPICC as well as MEDDIC?
Yes. MEDDICC adds Competition and MEDDPICC adds Paper Process and additional decision detail. Each extra element is simply another Brick with its own specific criterion: Competition evaluates whether a named competitor was mentioned and how the comparison was framed; Paper Process evaluates whether the buyer described the procurement steps required after a verbal agreement, such as legal review, security review, and contract approval. Adding them to a MEDDIC Kit is a versioned schema change, so the original six elements keep their criteria and output shape while the Kit grows to cover your full qualification model.
What happens when a MEDDIC element isn’t discussed on a call?
The Brick returns a "not established on this call" value rather than a failing score, because not covered and covered-but-absent are different facts. When the automation writes back to the CRM, a not-established result from one call doesn’t overwrite a positive score that was confirmed on an earlier call, so the field retains the best evidence from any conversation in the deal. The call-level result is preserved separately, which is what makes longitudinal scoring across the deal cycle possible rather than collapsing everything into a single overwritten field.
Can reps still override or annotate automated scores?
Most RevOps teams keep a separate rep-editable field alongside the automatically scored one, so reps can add context the transcript never captured, such as qualification shared over email or in an unrecorded conversation. The automated score reflects what Semarize found in the transcript, with the supporting quote attached; the rep-annotated field reflects additional context the rep holds. Keeping the two separate makes it obvious which evidence is system-sourced and which is rep-reported, which preserves the analytical value of the automated score for pipeline review without removing rep agency over the deal.
Does Semarize replace Gong or Chorus for this?
No. Semarize is supplemental to recording platforms like Gong and Chorus and adds a structured-output layer they don’t expose natively. It’s transcript-agnostic, so it accepts transcript text from Gong, Fathom, Zoom, Teams, Meet, or an upload, processes after the call, and returns typed JSON via API or webhook. Semarize isn’t a recorder, a call store, a coaching dashboard, or a rep-facing review UI; it is the layer that turns the conversation content those tools capture into MEDDIC scores your CRM and forecast models can use as data.
Continue reading
Read more from Semarize
MEDDICC Scoring From Discovery Calls
Most MEDDICC data is stale before it reaches CRM. Reps update fields from memory after the call, introducing timing gaps and sampling bias that make qualification scores unreliable. Extracting MEDDICC signals directly from transcripts fixes the data freshness problem that better training never will.
5 Ways to Automate MEDDIC Scoring Directly From Sales Calls
Automated MEDDIC scoring from sales call transcripts removes rep compliance and recall from the equation entirely. Here are five concrete approaches, from no-code Make and n8n flows to direct API integration and Salesforce Flow orchestration.
CRM Enrichment From Sales Calls: The RevOps Data Ops Playbook
Most CRM enrichment stalls at 30% field coverage because the output is unstructured - reps updating from memory, summaries stored as notes. The fix is a structured extraction pipeline: transcript to consistent fields to CRM to automation triggers. This playbook covers the schema, the routing, and the implementation in Salesforce and HubSpot.