Start Evaluating Agents the Way You Should Be Evaluating Humans
If you're running structured evaluation on every human rep conversation, you already know what a deterministic rubric produces: typed JSON, one field per Brick, the same result every time the same call runs. Your AI agent is now handling conversations that look structurally identical to the ones you evaluate. Qualification discussions, commercial objections, product questions. The same evaluation you run on every human rep call doesn't run on any of them. That gap doesn't stay visible. It stays invisible until a claim the agent made confidently turns out to be wrong, or a pattern of unqualified buyers slips through without showing up in the conversation data.
The default response is to accept what the vendor provides: completion rates, sentiment scores, escalation counts. These tell you how the agent performed against the vendor's model of a good interaction. They say nothing about whether the agent is qualifying buyers against your criteria, staying within the bounds of your approved product claims, or handling commercial discussions the way your methodology requires. Vendor metrics and your evaluation standards are not the same thing, and treating them as equivalent is what keeps the gap open.
Why the usual alternatives don't fill the gap
Manual annotation doesn't scale to the volume AI agents generate, and it falls further behind each time the vendor updates their model. LLM-as-judge returns freeform prose: analysis you can read but can't threshold, can't route to alerts, and can't trend over time in a way that tells you whether quality is improving or deteriorating. Keyword matching catches surface patterns but misses semantic quality. An agent can use the right words in an order that produces a wrong claim and the match returns green. None of these approaches produce what your human rep evaluation already produces: a locked schema, running the same checks, returning the same structured output every run. The evaluation contract framing covers why schema stability is the variable that separates scoring you can act on from scoring you can only read.
Why hallucinations need grounded evaluation to surface
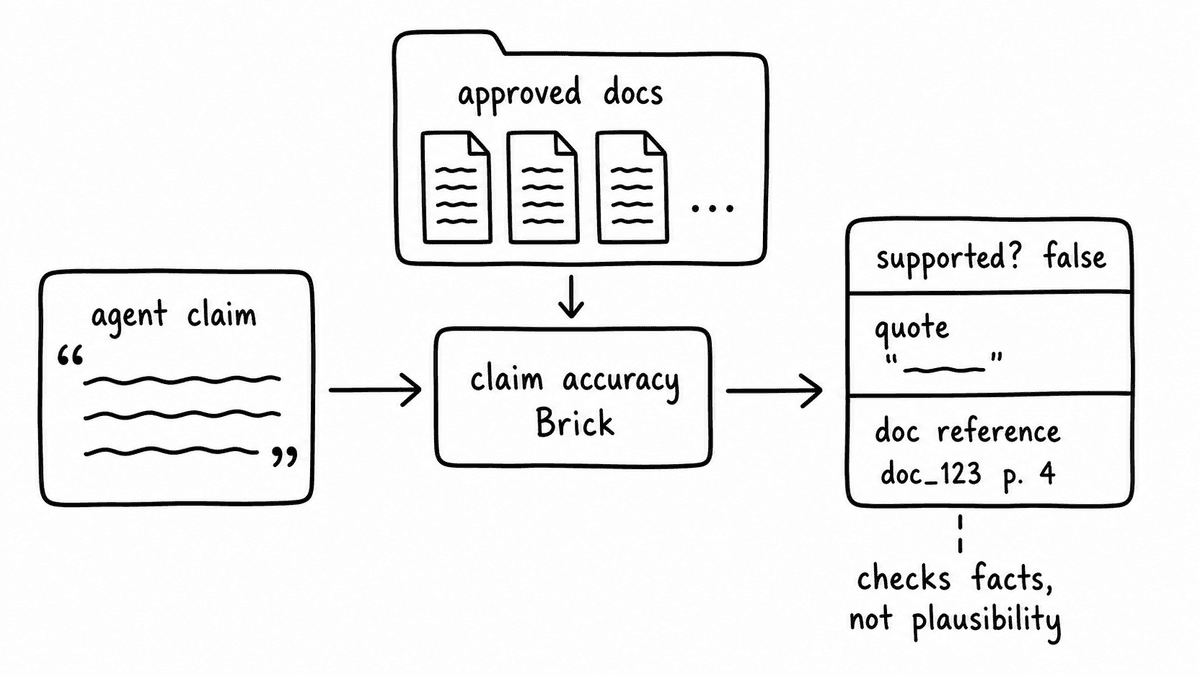
The specific failure mode that matters most is the confident wrong claim: the agent states something that sounds accurate, receives no pushback, scores plausible under impression-based evaluation, and is only identified as wrong when a downstream consequence makes it visible. Without grounding the evaluation in your approved content, there is no mechanism to catch this at scale. The evaluation is assessing whether the response was plausible, not whether it was accurate against your actual documents.
Grounded evaluation changes this. When the Brick checking claim accuracy has access to your approved product documentation, it compares what the agent stated against what you have defined as correct. A claim that isn't supported by the approved content gets flagged, with the transcript evidence and the document reference. This applies across the dimensions your deployment requires: product claims checked against your documentation, pricing checked against your rate card, qualification criteria checked against your ICP definition. Each Brick addresses one dimension; each is grounded in the document that defines the correct answer for that dimension. The knowledge grounding framing covers why the document layer is what makes the difference between evaluation that checks facts and evaluation that infers them.
Drift monitoring: catching quality changes before customers do
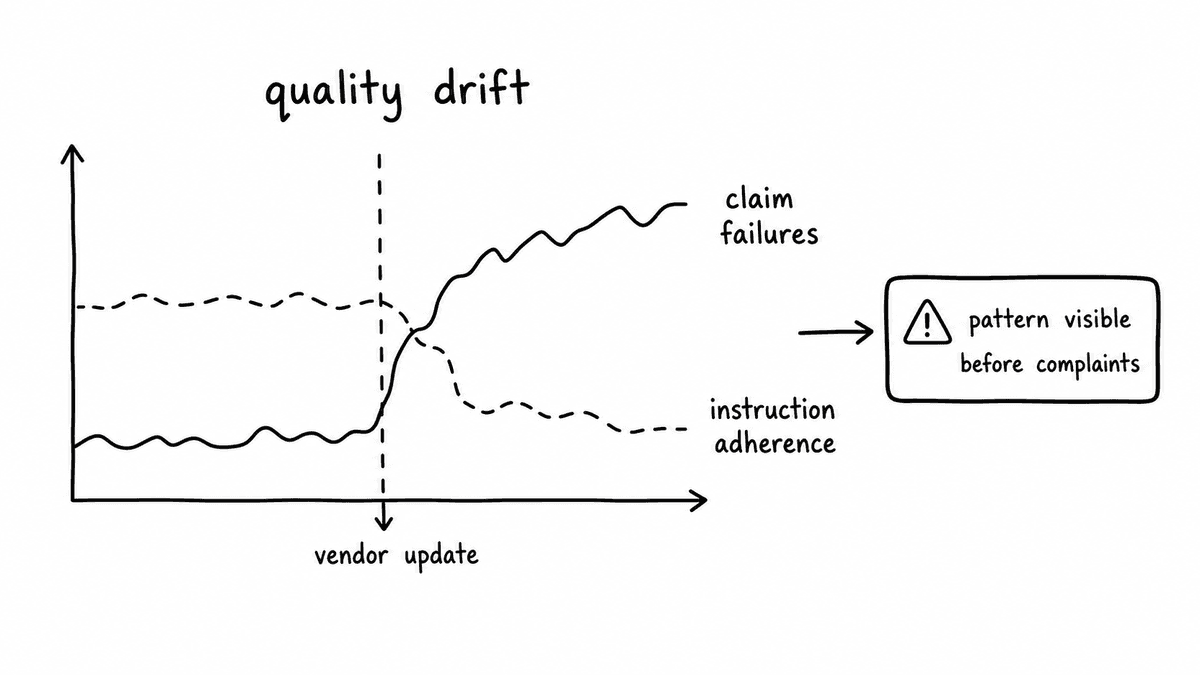
Vendor model updates aren't always announced with enough specificity to tell you whether they affect the dimensions you care about. Without a locked evaluation schema running on 100% of production conversations, quality changes after an update are invisible until a pattern of complaints accumulates. By that point the problem has been running for weeks.
A deterministic evaluation contract gives you the baseline to detect this. Because the same schema runs against every conversation and produces the same output structure, you can track field distributions over time. If instruction adherence scores shift after a model update, or grounding failures on product claims increase, the pattern is visible in the data before it reaches customers. The evaluation doesn't tell you what changed in the vendor's model. It tells you what changed in the agent's behaviour against your standards.
How Semarize handles this
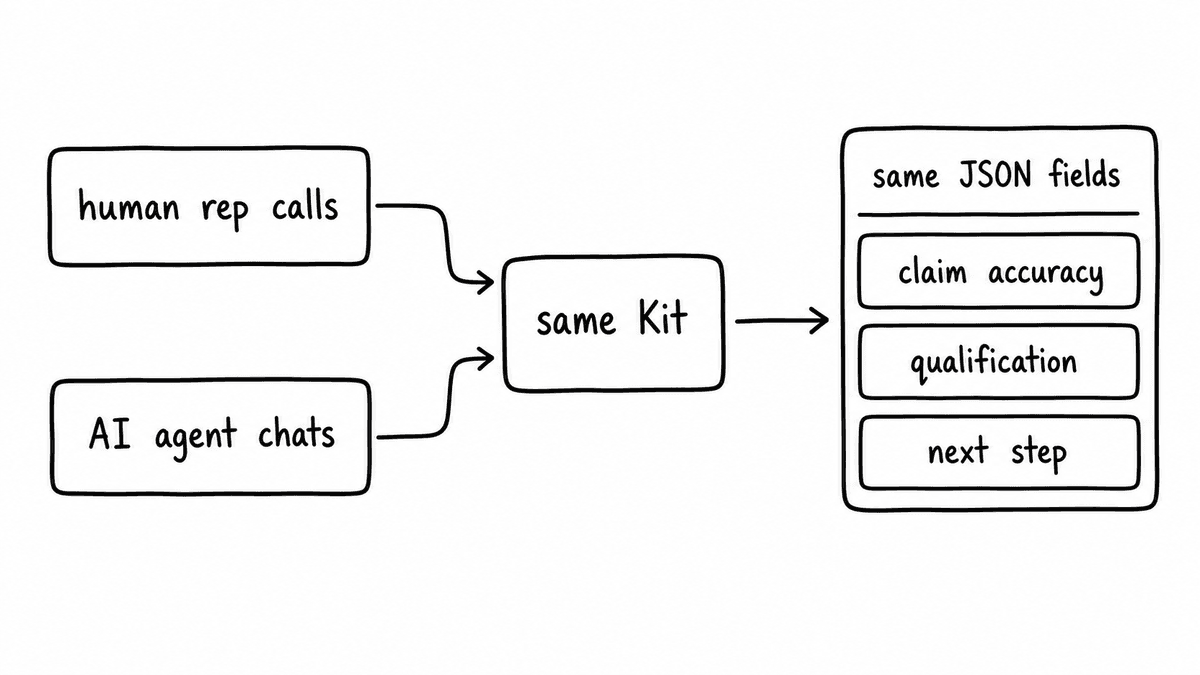
The evaluation contract in Semarize is separate from the conversation source. The same Kityou use to evaluate human rep calls runs against AI agent conversations without changes to the schema. Each Brick asks one specific question and accesses only the knowledge relevant to that question: a claim accuracy Brick reads your approved product documentation, a qualification Brick reads your ICP criteria, a methodology Brick reads your playbook. Because the Kit is versioned in the app, it doesn't change when the vendor updates their model. What changes after an update becomes visible in the output distributions, not in a changed evaluation definition.
The output is the same structured JSON your human rep evaluation produces: one named field per Brick, each with a typed value, confidence, reason, and evidence from the conversation. The same dashboards, the same CRM routing logic, and the same coaching workflows apply to AI agent conversations as to human ones. You're not building separate infrastructure to evaluate a different conversation source. You're applying the same contract to a larger set of conversations, scored the same way, at 100% of production volume. The AI evaluation use case covers the full signal architecture, including how structured outputs route to dashboards, alerts, and downstream systems.
Apply your evaluation contract to every conversation your AI agent produces, the same way you apply it to your humans.
Common questions
We already score human reps. What does it take to apply the same evaluation to AI agent conversations?
If you have a Kit built for human rep calls, the evaluation contract is already defined. The same Kit runs against an AI agent transcript without changes to the schema. What you're adding is a new conversation source feeding the same input: transcript in, structured JSON out. The fields, grounding documents, and output types stay the same. The practical work is connecting the AI agent transcript to the evaluation pipeline, not rebuilding the rubric. If your current Kit was built around rep behaviour rather than buyer signals or claim accuracy, it's worth reviewing the Bricks before extending it, but the architecture doesn't change.
How do you ground hallucination detection in a company knowledge base?
Each Brick that checks for a factual claim is attached to the document that defines what the correct claim looks like. A Brick checking product claim accuracy reads your approved product documentation. A Brick checking pricing accuracy reads your rate card. The Brick compares what the agent stated against what's in the document and returns a boolean flag with the transcript quote and the document reference as evidence. The key discipline is keeping each grounding document bounded in purpose: a document that covers too many things gives the Brick too broad a scope to check precisely. One question, one document, one Brick is the pattern that produces auditable hallucination detection.
Can LLM-as-judge still be used if the outputs are structured JSON?
Yes. The issue with LLM-as-judge isn't the LLM: it's that most implementations ask the judge to return freeform prose, which can't be thresholded, trended, or routed. When the judge is constrained to return structured JSON with defined fields (a boolean for pass/fail, a score within a defined range, a text field for the specific evidence), the output is operationalizable. The evaluation contract defines what the judge is allowed to return; the LLM executes the check. The stability comes from the schema, not from replacing the LLM with a different mechanism.
What does quality drift monitoring measure and how often should it run?
Quality drift monitoring tracks the distribution of evaluation field values over time against a baseline. For each Brick in your Kit, you establish a baseline distribution (what scores and pass rates look like in a normal production period), then monitor for statistically meaningful shifts. A drop in instruction adherence pass rate, an increase in grounding failures, or a shift in score distributions on specific dimensions signals a change in agent behaviour. For high-volume deployments, daily aggregates catch changes within a day or two of a model update. For lower-volume deployments, weekly cohort comparisons against the baseline serve the same purpose.
How do we compare human rep and AI agent performance on the same dimensions?
Because the same Kit runs against both conversation sources and produces the same field structure, the comparison is a direct output of running the evaluation at scale. You don't need a separate benchmarking process. Pull the field distributions for human rep conversations and AI agent conversations across the same period and compare them dimension by dimension. Where the agent outperforms on instruction adherence, that's signal on where the human motion has gaps. Where the agent underperforms on claim accuracy, that's where the grounding documents or agent prompts need tightening. The shared evaluation contract is what makes the comparison interpretable rather than directional.
Continue reading
Read more from Semarize
Conversation Intelligence for Developers: Don't Build a Fragile Pipeline, Don't Buy a Black Box
Most teams don't fail to add conversation intelligence because the model is bad; they fail because the integration is fragile and unstructured. The fix isn't a better LLM pipeline or a platform API you can't control. It's a layer that takes a transcript, runs it against a versioned Kit, and returns deterministic typed JSON you can test, version, and route into your product.
AI Scorecards Don't Disagree. Your Prompt Does.
Inconsistent AI scorecards aren't an AI problem - they're a process failure. Freeform prompts ask the model to re-interpret evaluation criteria on every run, and that interpretation drifts with phrasing, model updates, and context. The fix is an evaluation contract: a locked schema with defined output types that produces the same result on the same call, every time.
Bricks and Kits: the mechanism for stable conversation evaluation
Freeform prompts produce inconsistent evaluation results - scores drift, output shapes change, and you can't tell whether coaching improved anything or whether the rubric moved. Bricks define a locked evaluation schema: one question, one output type. Kits group them into reusable evaluation workflows. The result is schema-stable conversation analysis you control.